Wang Shusen Recommender Systems Study Notes — Feature Crossing
Wang Shusen Recommender Systems Study Notes — Feature Crossing
Feature Crossing
Factorization Machine (FM)
Linear Model
-
Given features, denoted as .
-
Linear model:
-
The model has parameters: and .
-
Prediction is a weighted sum of features. (Addition only, no multiplication.)
Second-Order Crossed Features
-
Given features, denoted as .
-
Linear model + second-order crossed features:
-
The model has parameters.
Linear model + second-order crossed features:
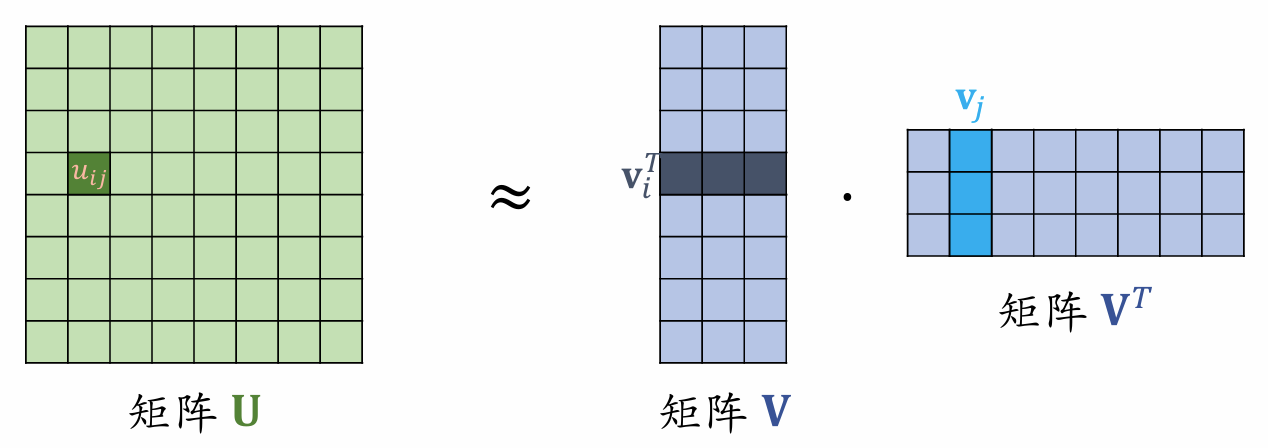
Matrix has rows and columns; matrix has rows and columns; matrix has rows and columns.
-
Factorization Machine (FM):
-
FM has parameters. ()
Factorization Machine
- FM is a drop-in replacement for linear models; anywhere linear regression or logistic regression can be used, FM can be used instead.
- FM uses second-order crossed features, making it more expressive than linear models.
- Through the approximation , FM reduces the number of second-order cross weights from to .
Deep & Cross Network (DCN)
Retrieval and Ranking Models
Two-tower models and multi-objective ranking models are just structural frameworks; the internal neural networks can be any network architecture.
Cross Layer
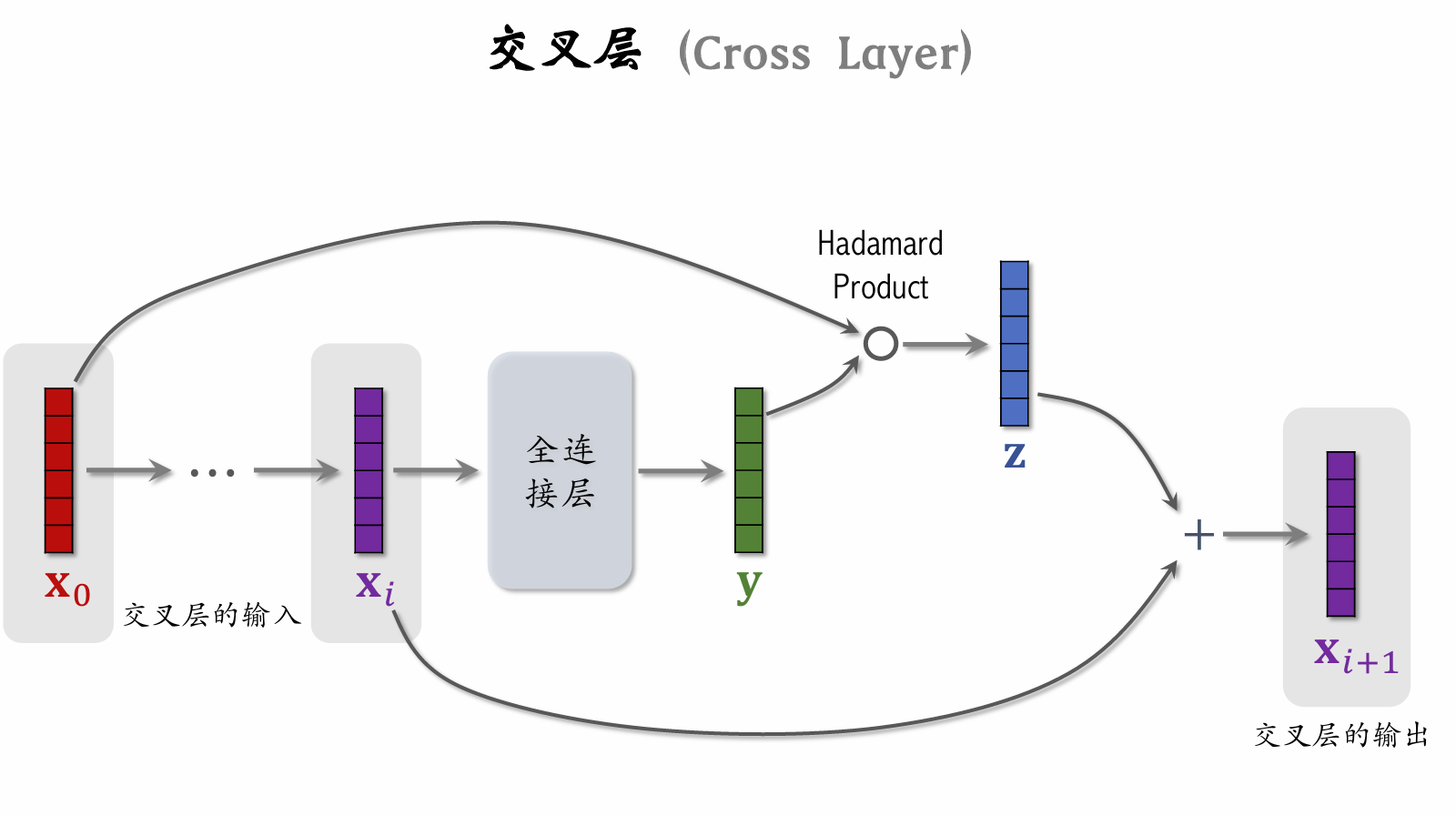
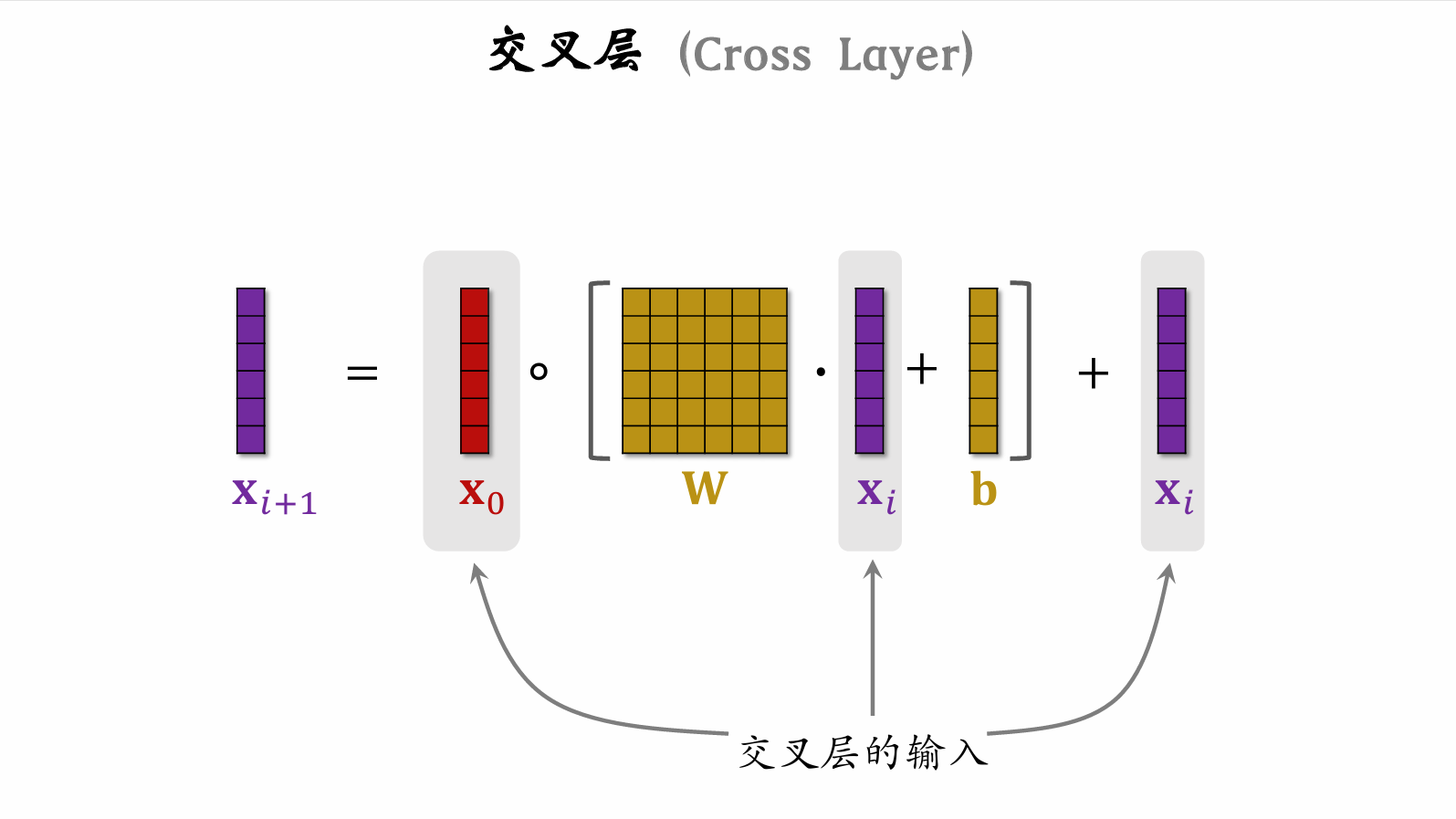
Incorporates ResNet concepts to prevent vanishing gradients.
Cross Network
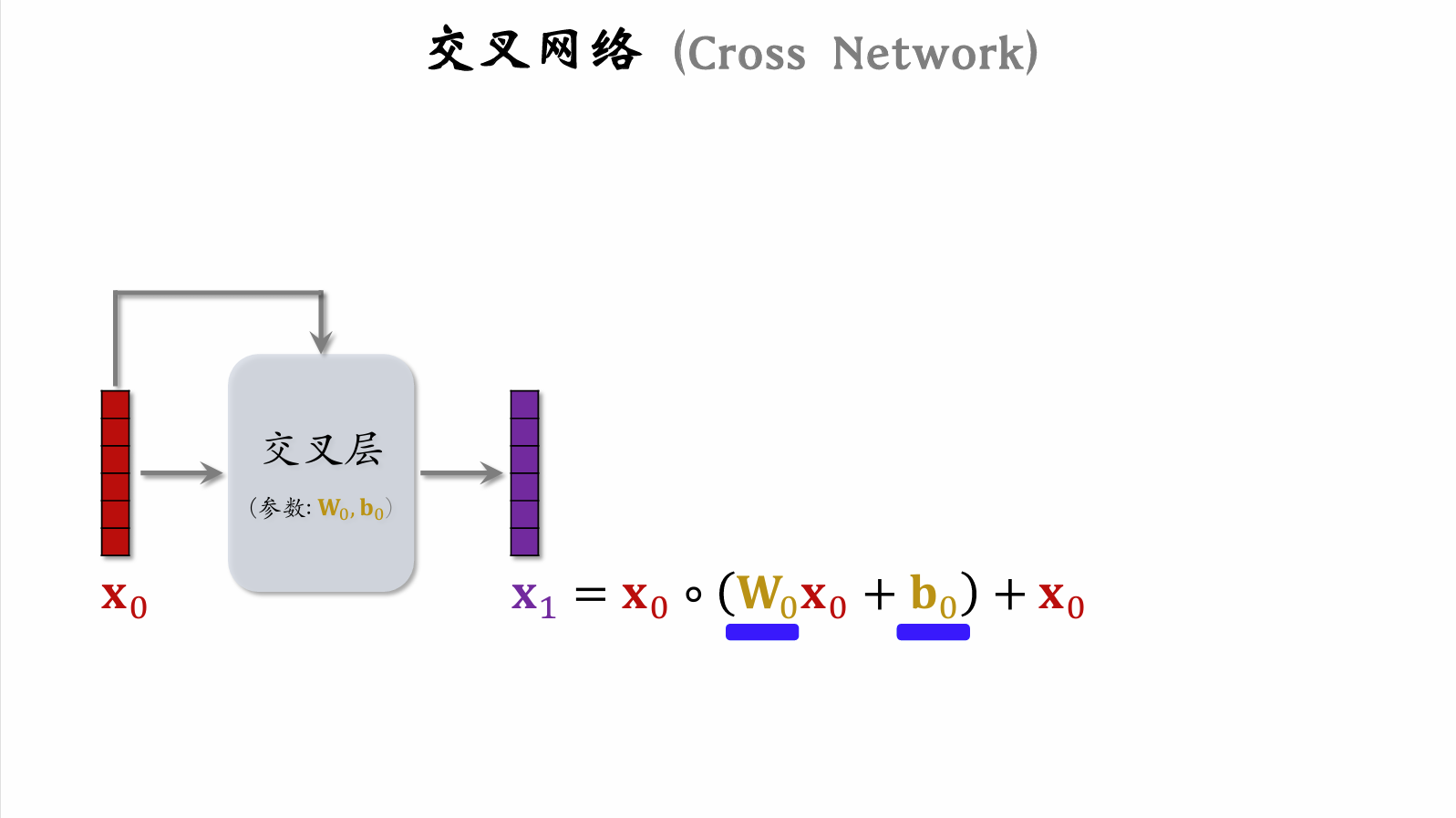
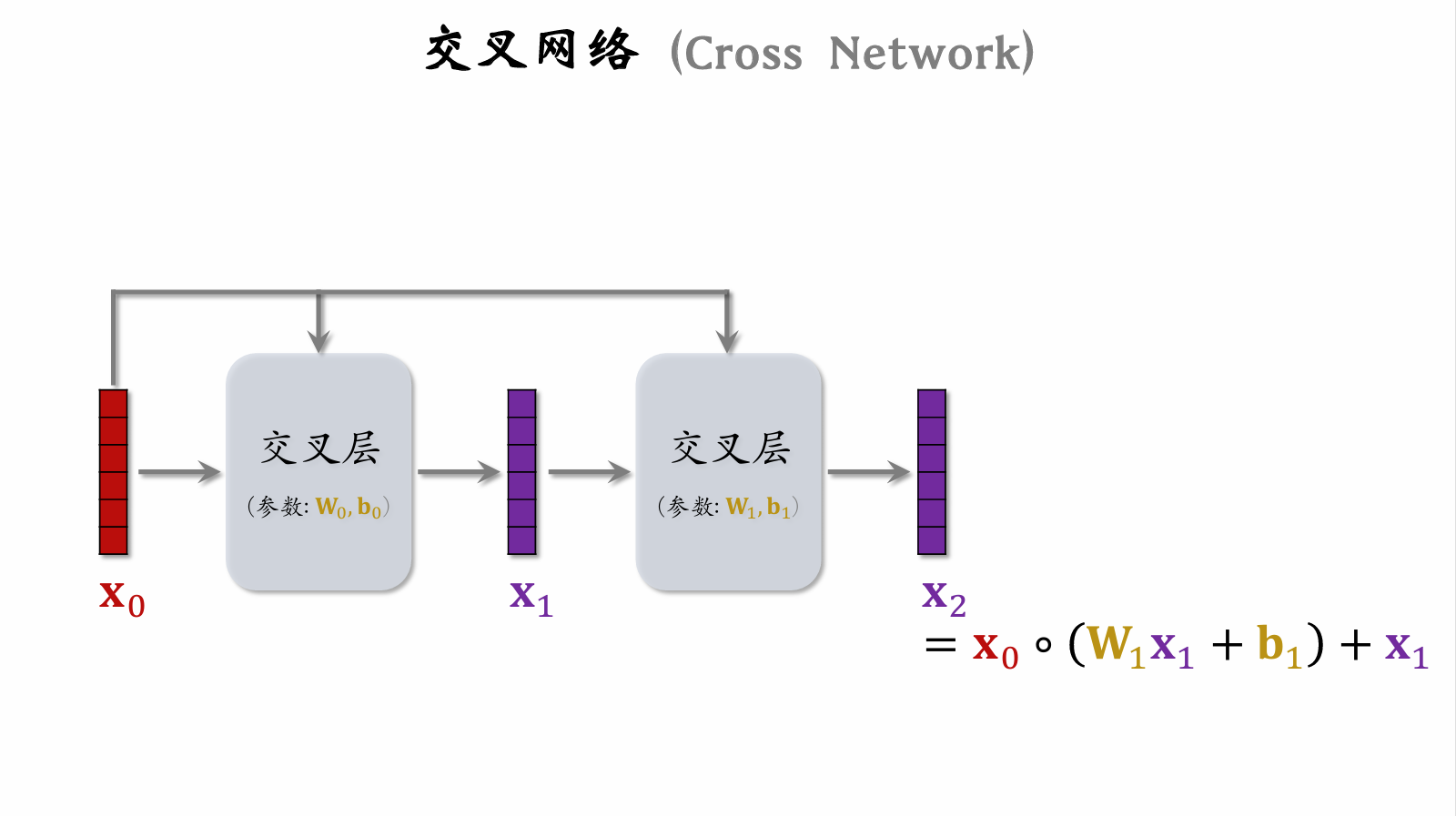
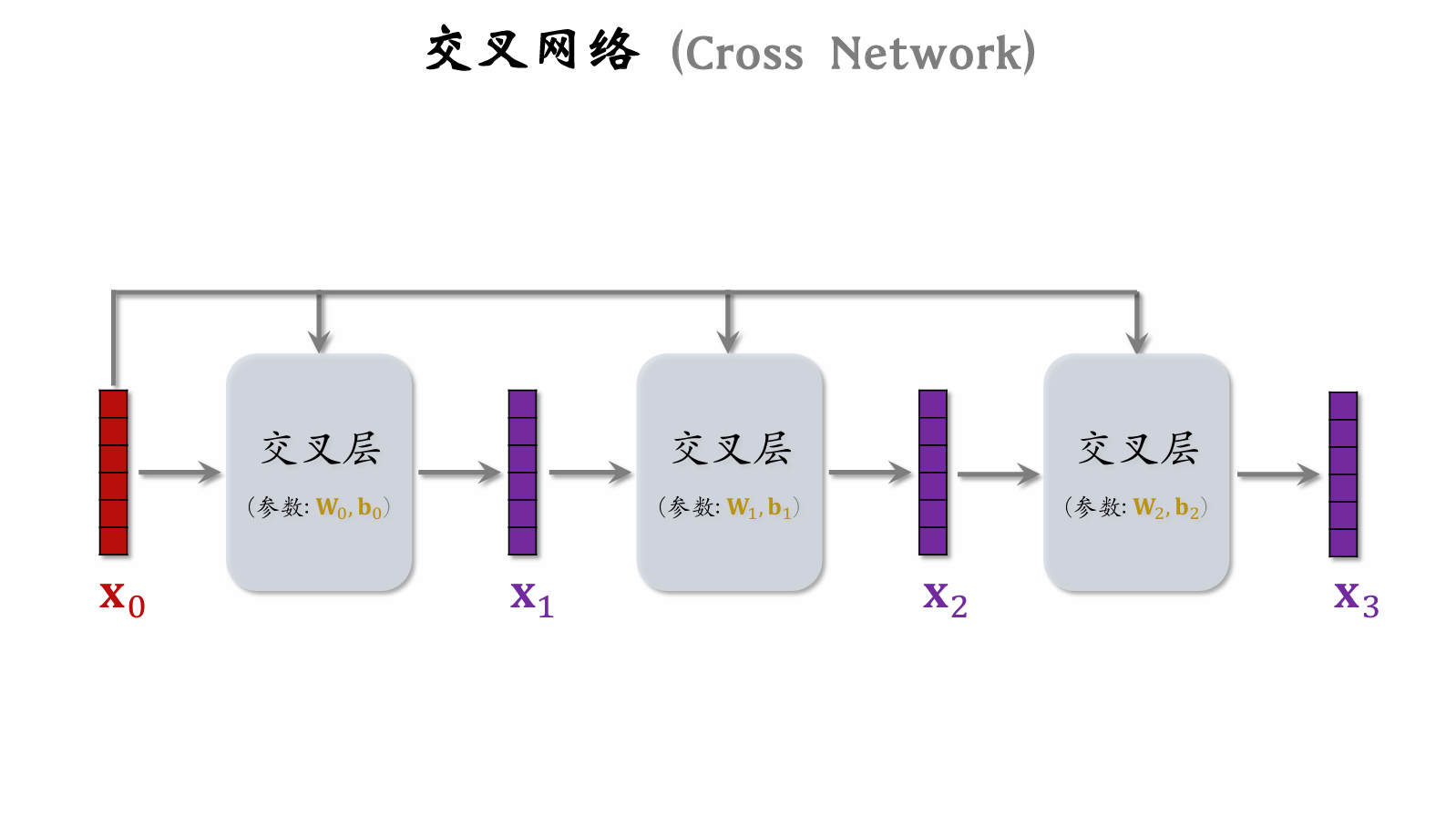
Deep & Cross Network (DCN)
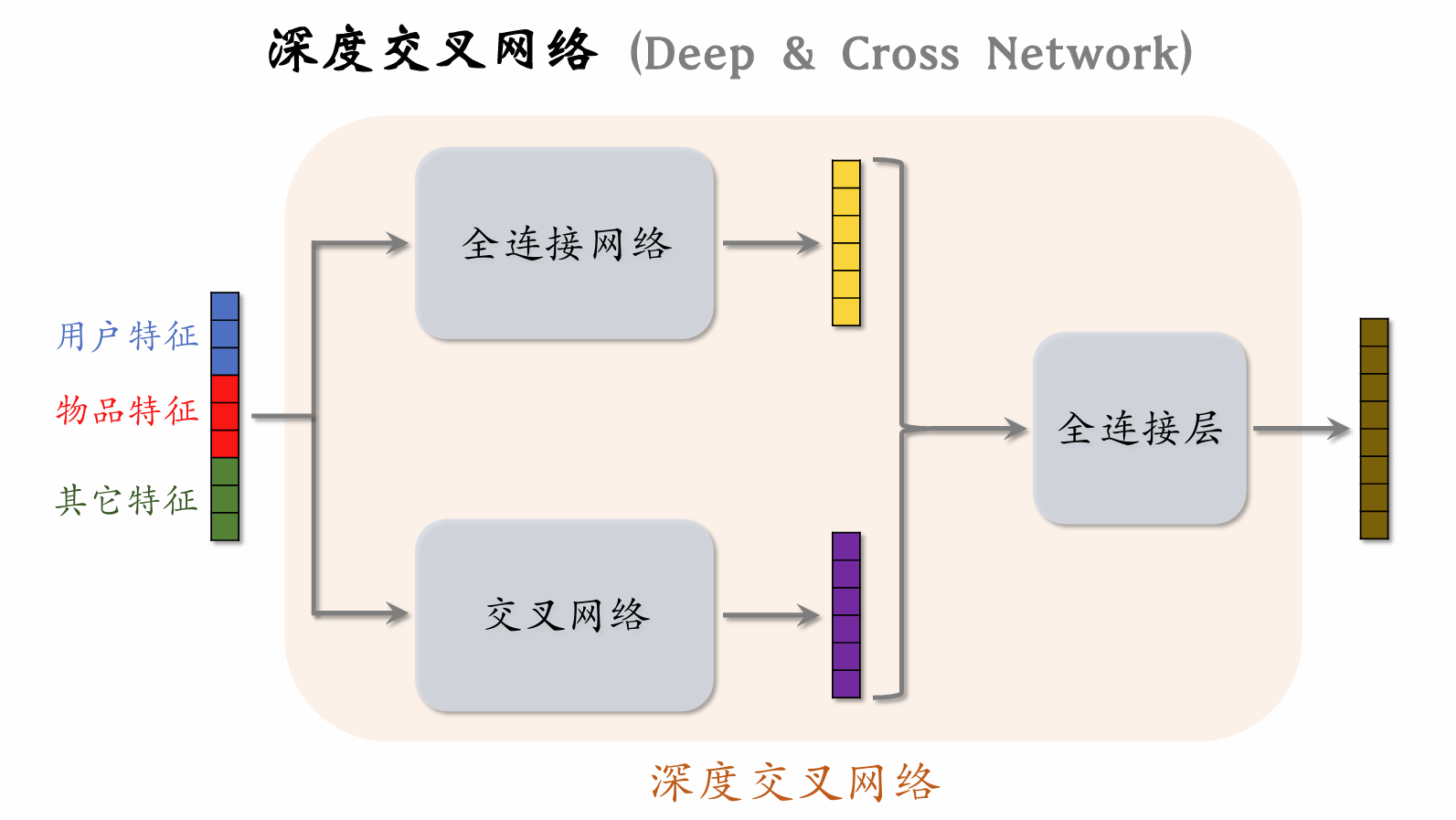
DCN outperforms fully connected networks in practice and can be used in the user tower and item tower of two-tower models, the shared bottom network of multi-objective ranking models, and the expert networks in MMoE.
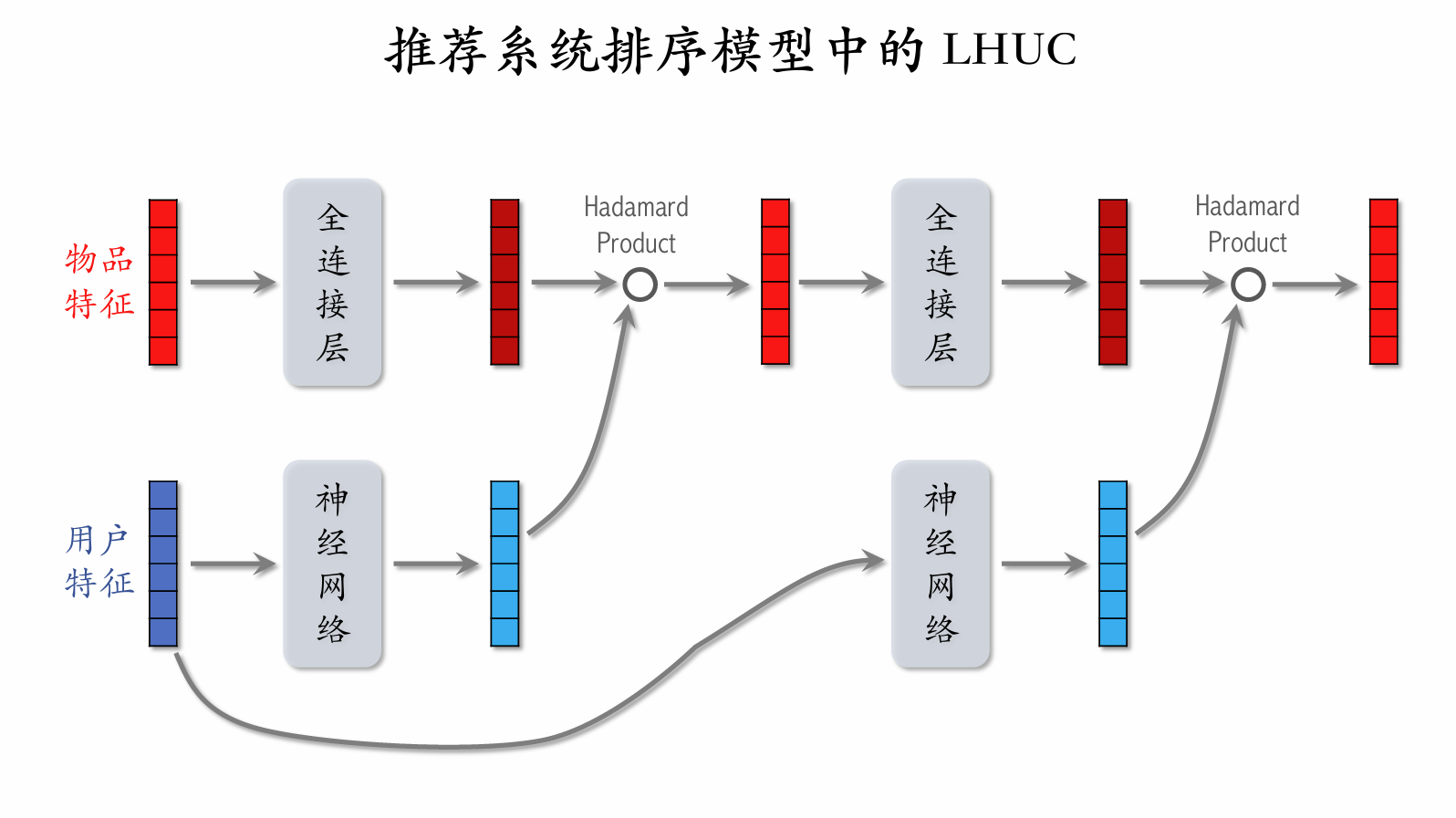
Learning Hidden Unit Contributions (LHUC)
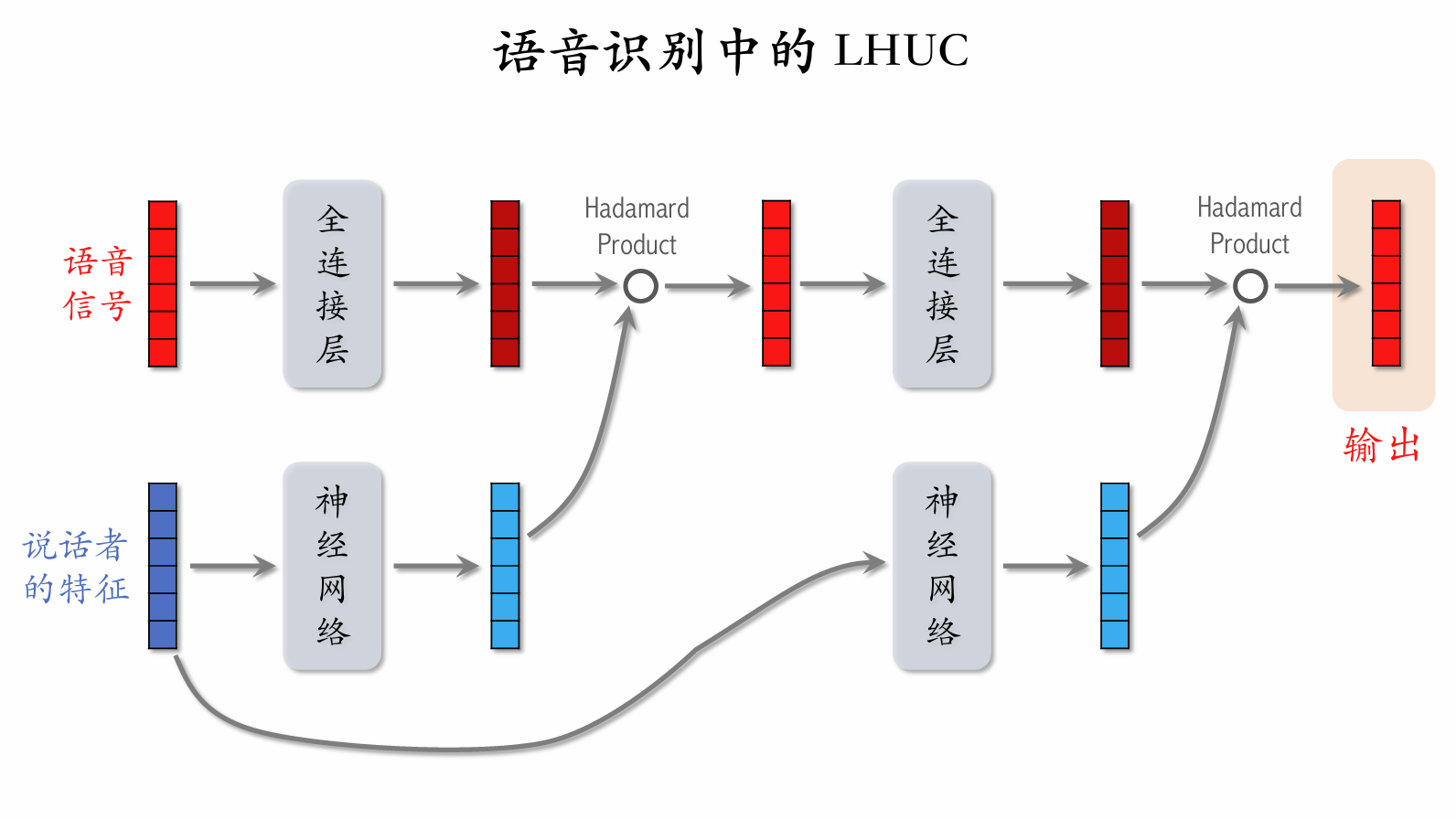
The neural network structure is [multiple fully connected layers] → [Sigmoid × 2], so all values in the output vector lie between 0 and 2.
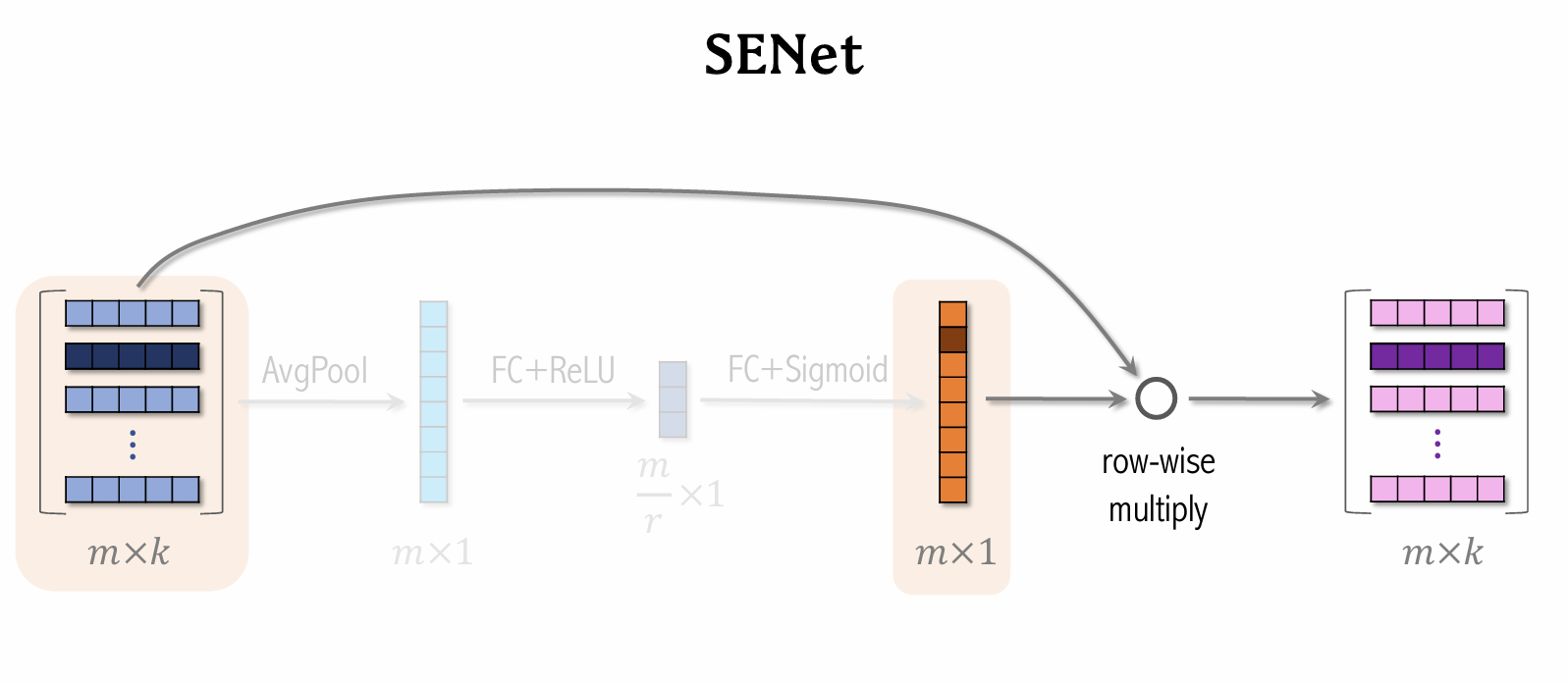
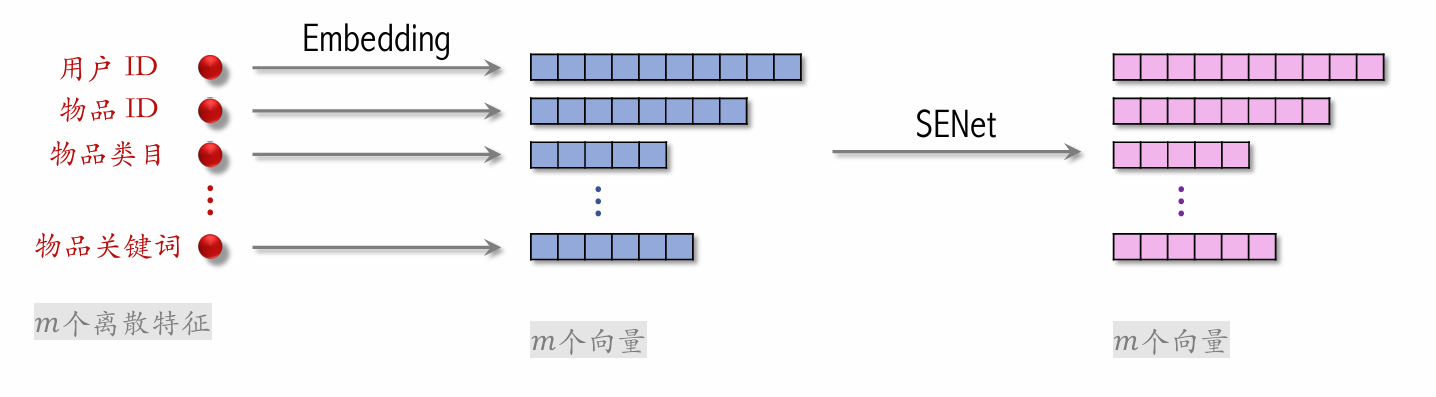
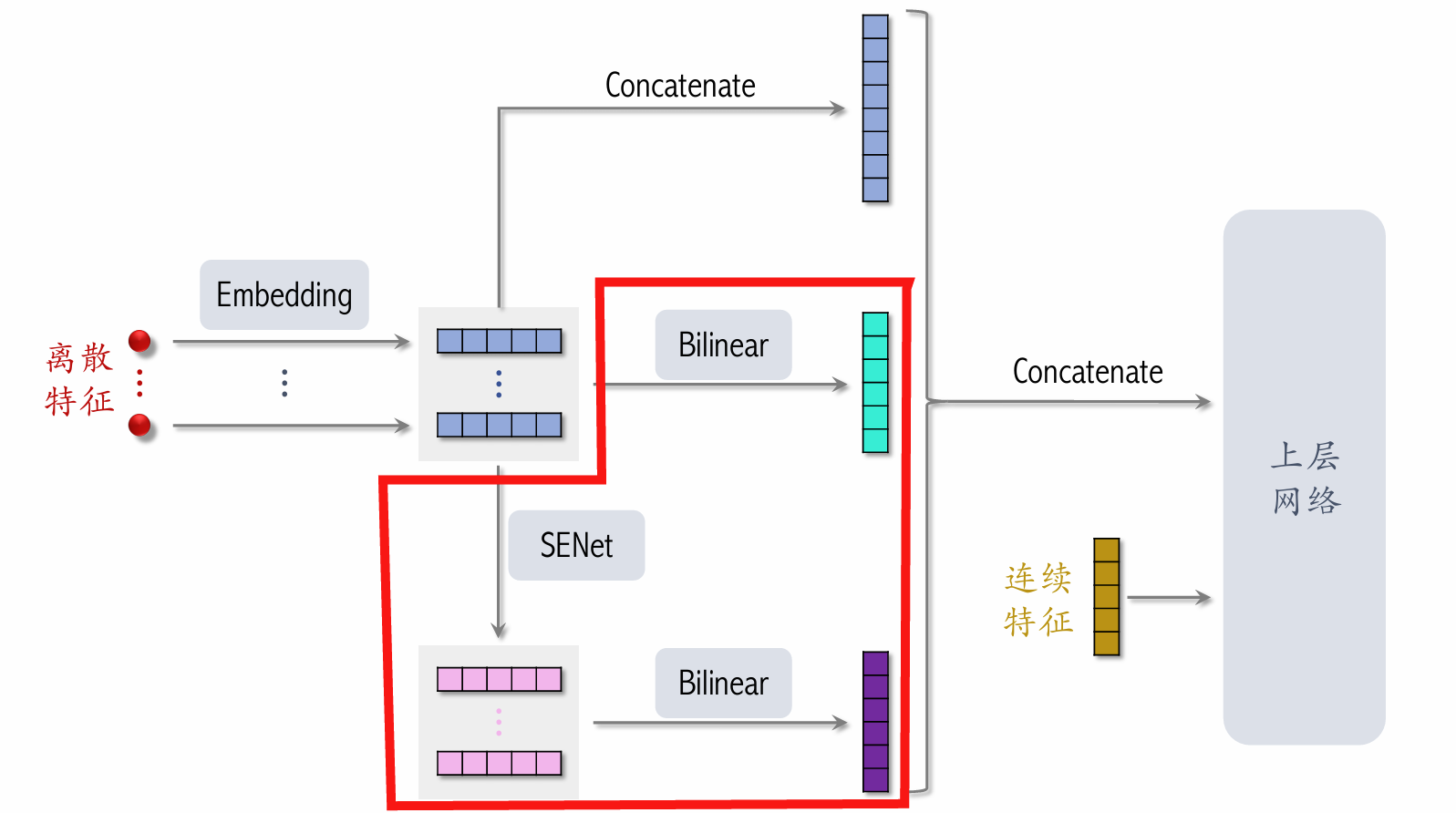
SENet & Bilinear Cross
-
SENet applies field-wise weighting to discrete features.
-
Field:
- User ID embedding is a 64-dimensional vector.
- The 64 elements (i.e., the embedding vector of one feature) form one field and receive the same weight.
- The more important the feature, the higher the weight.
-
If there are fields, the weight vector is -dimensional.
Cross-Field Feature Crossing
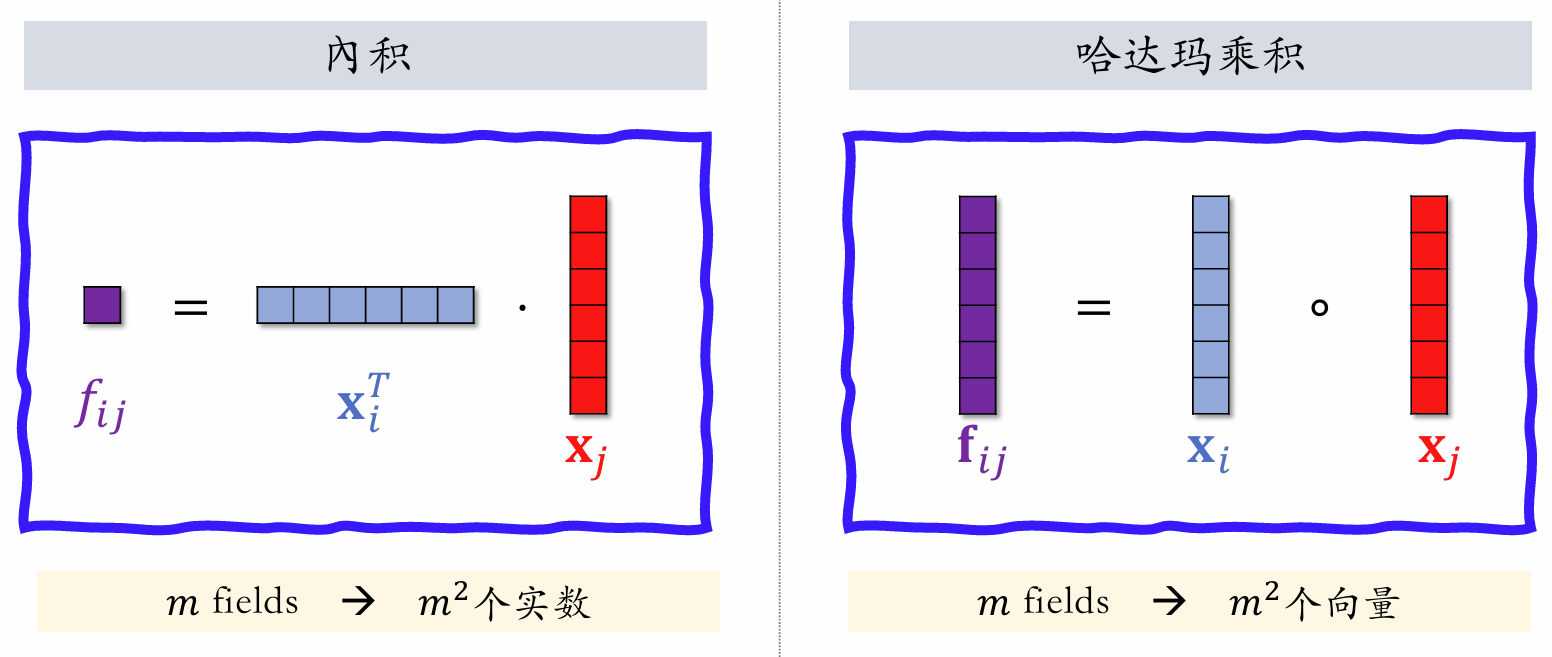
Inner Product
Both and are feature embedding vectors; is a scalar. With fields, pairwise inner products yield scalars.
Hadamard Product
Both and are feature embedding vectors; is a vector. With fields, pairwise Hadamard products yield vectors — too many. One must manually specify which vector pairs to cross, rather than crossing all pairs.
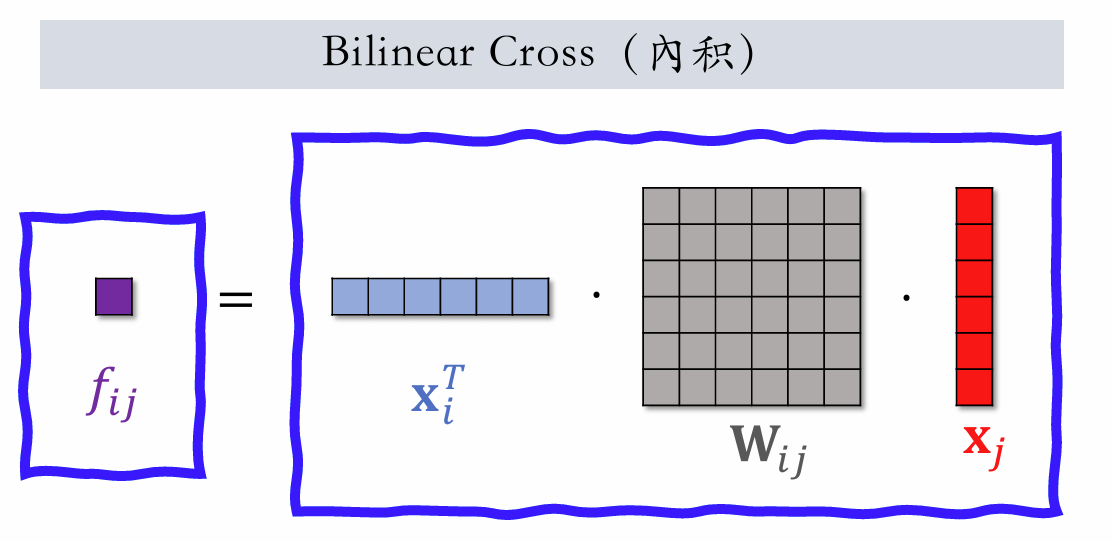
Bilinear Cross (inner product)
With fields, there are scalar values and parameter matrices .
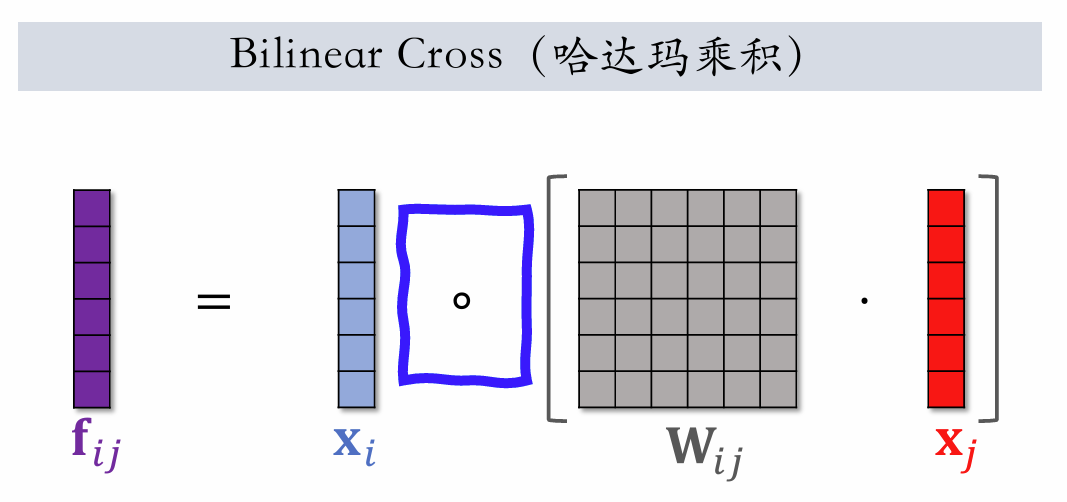
Bilinear Cross (Hadamard)
With fields, there are vector values and parameter matrices .
FiBiNet
Behavior Sequences
User Behavior Sequence Modeling
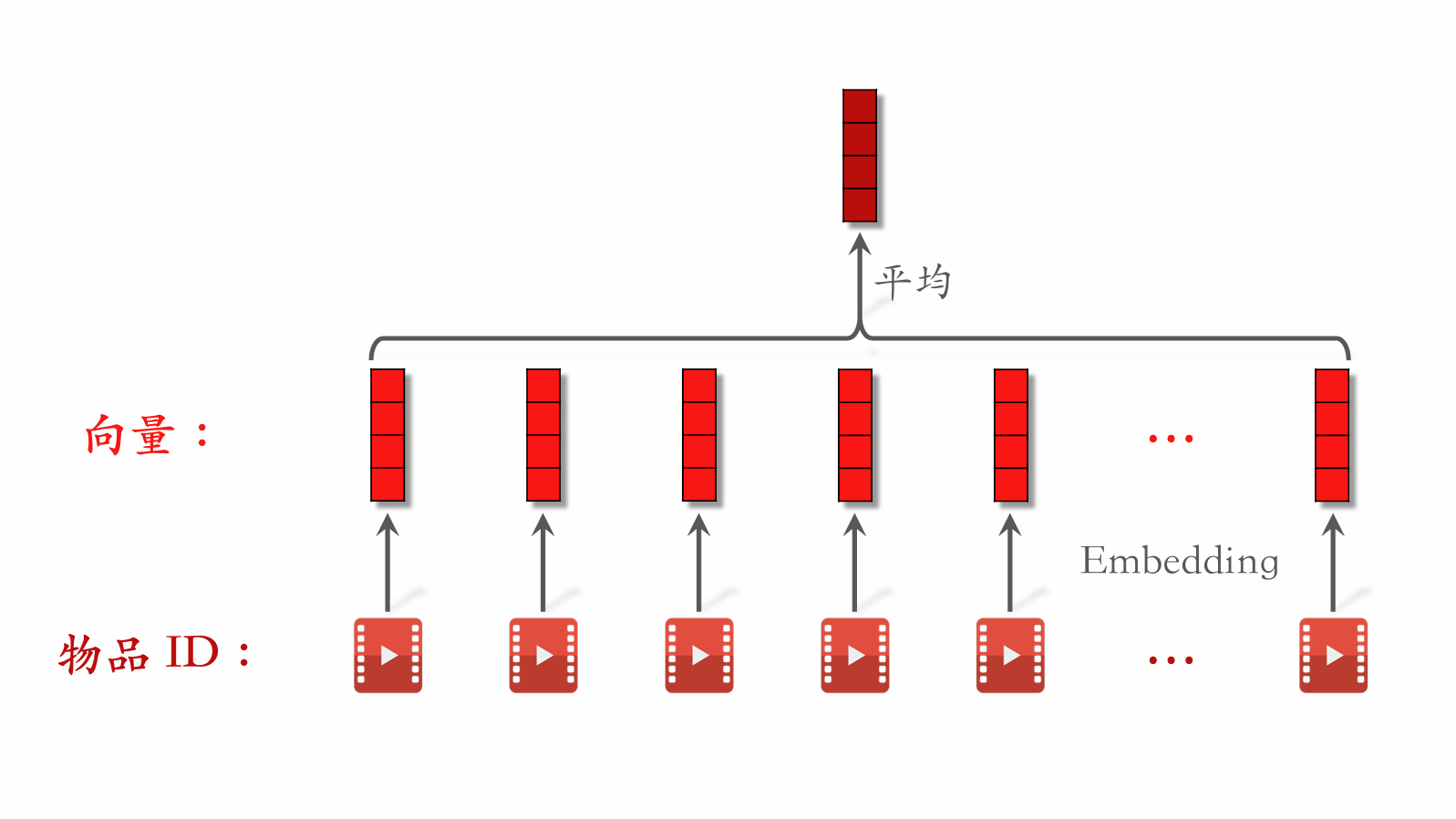
LastN Features
- LastN: Item IDs from the user's most recent interactions (clicks, likes, etc.).
- Embed LastN item IDs to get vectors.
- Take the average of these vectors as one type of user feature.
- Applicable to retrieval two-tower models, pre-ranking three-tower models, and full-ranking models.
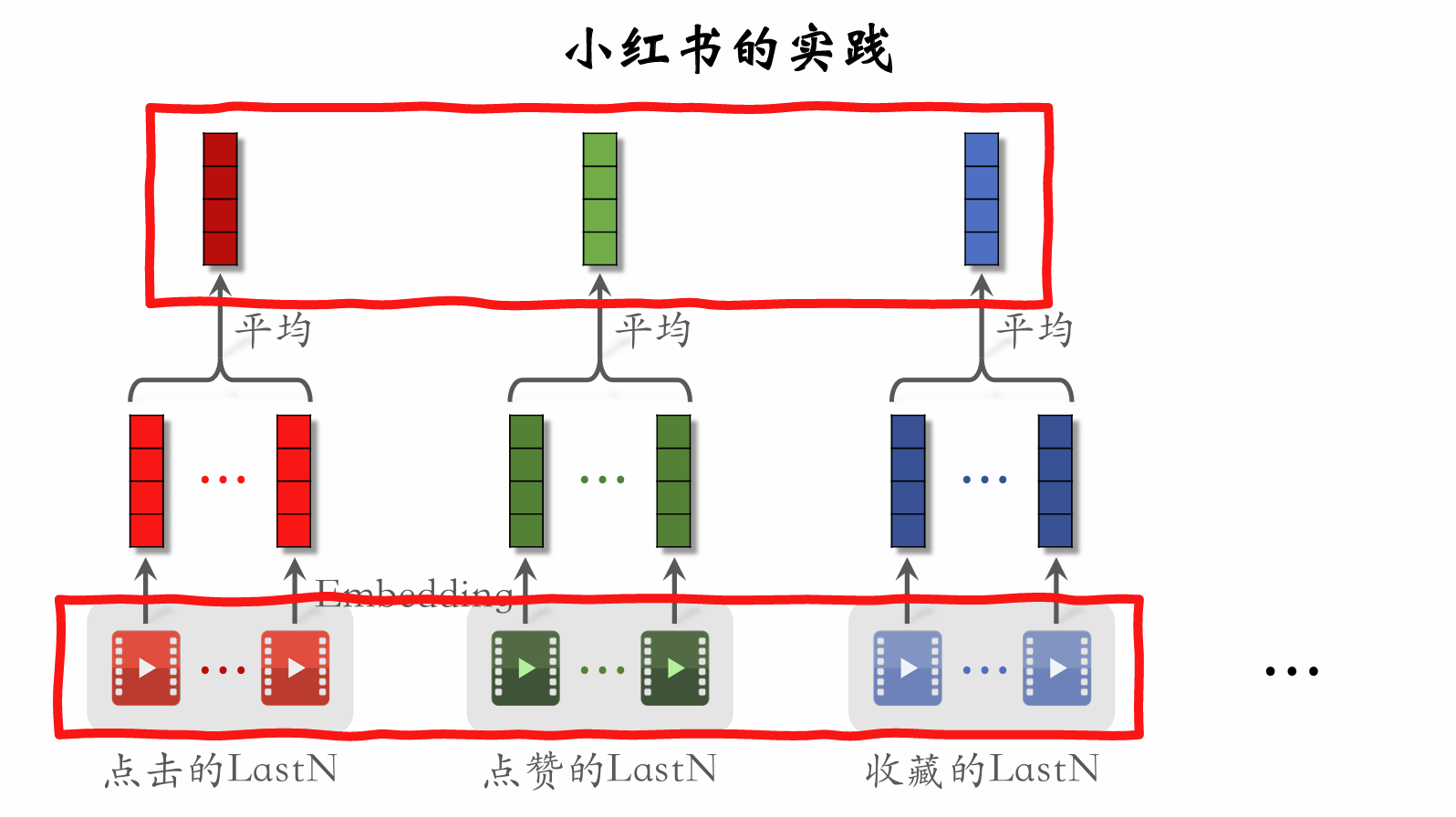
DIN Model
DIN Model
- DIN replaces simple averaging with weighted averaging, i.e., an attention mechanism.
- Weights: similarity between the candidate item and the user's LastN items.
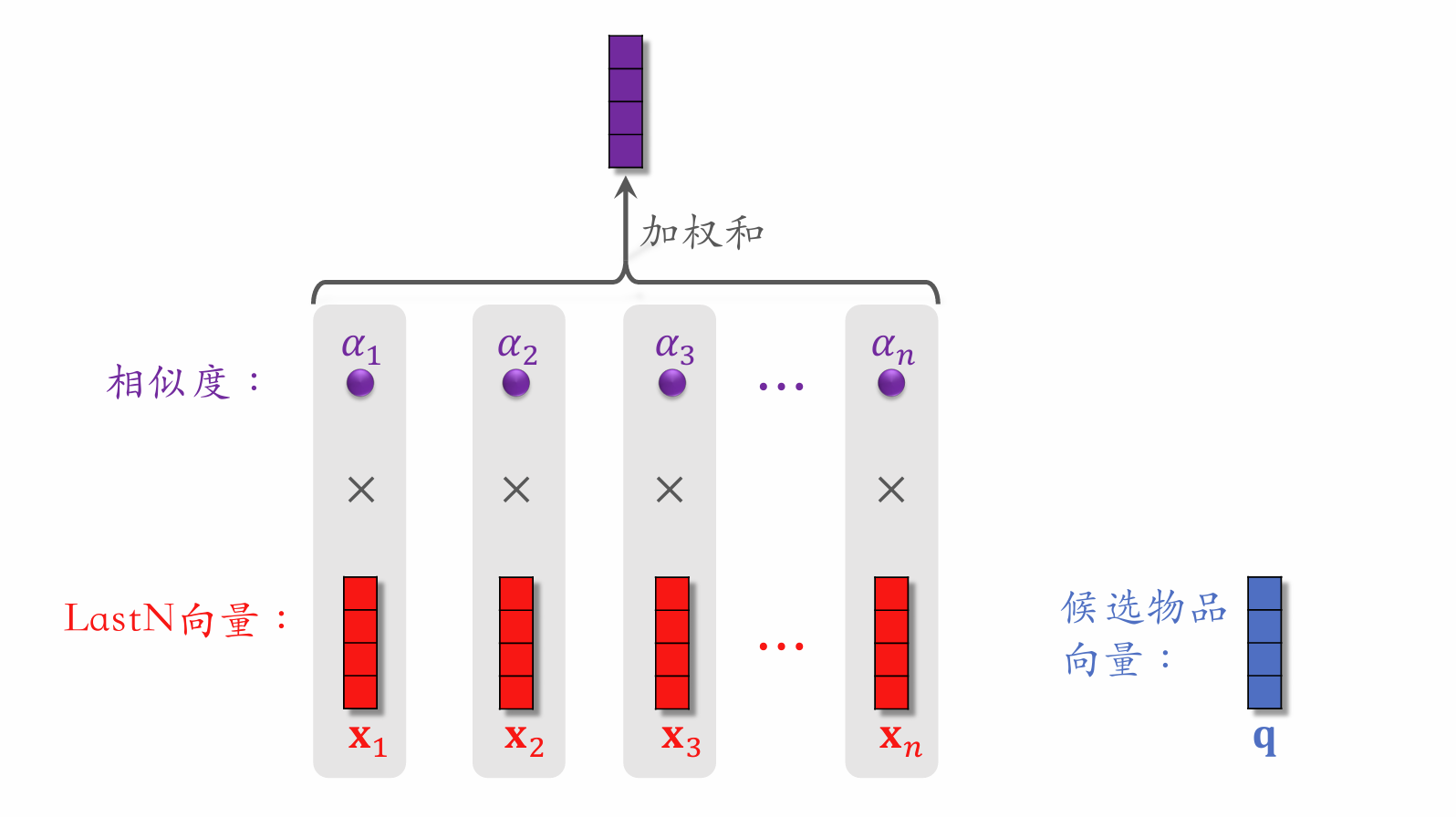
DIN Model
- For a given candidate item, compute its similarity to each of the user's LastN items.
- Use the similarity as weights to compute a weighted sum of the user's LastN item vectors, yielding a single vector.
- Use this vector as a user feature input to the ranking model, estimating click-through rate, like rate, etc. for (user, candidate item) pairs.
- This is essentially an attention mechanism.
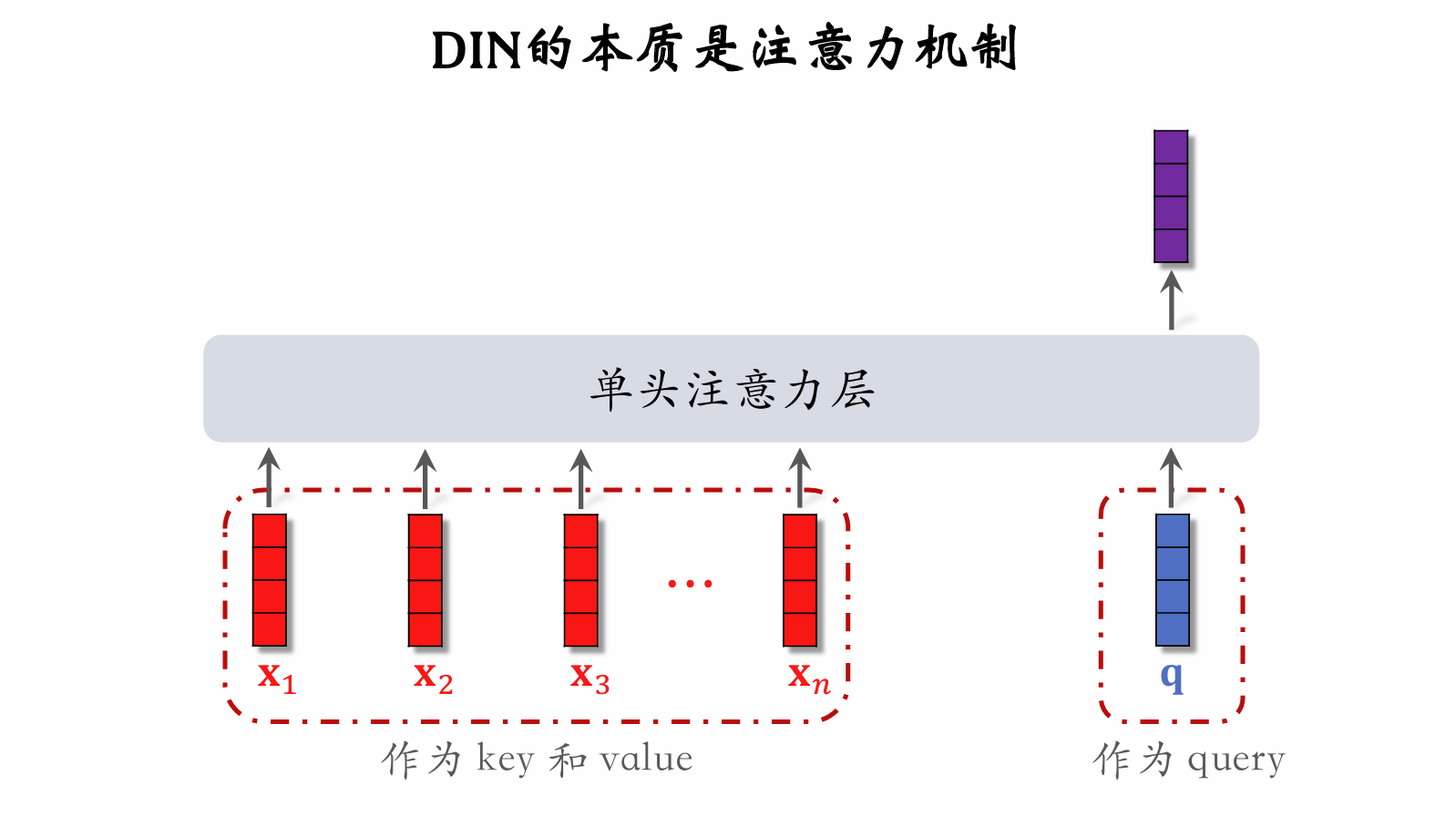
Simple Averaging vs. Attention Mechanism
- Both simple averaging and attention mechanism are applicable to full-ranking models.
- Simple averaging is applicable to two-tower and three-tower models.
- Simple averaging only uses LastN, which is a user-intrinsic feature.
- The average of LastN vectors is used as input to the user tower.
- Attention mechanism is not applicable to two-tower or three-tower models.
- Attention mechanism requires LastN + candidate item.
- The user tower cannot see the candidate item, so attention mechanism cannot be applied inside the user tower.
SIM Model
DIN Model
- Computes a weighted average of the user's LastN vectors.
- Weights are the similarity between the candidate item and each LastN item.
DIN Model Drawbacks
- Attention layer computation (length of user behavior sequence).
- Can only record the most recent few hundred items; otherwise computation is too expensive.
- Drawback: Focuses on short-term interests, forgetting long-term interests.
How to Improve DIN?
-
Goal: Retain long user behavior sequences ( large) without excessive computation.
-
Improved DIN:
- DIN computes a weighted average of LastN vectors using similarity as weights.
- If a LastN item is very different from the candidate item, its weight is near zero.
- Quickly eliminate LastN items unrelated to the candidate item, reducing computation in the attention layer.
SIM Model
- Retains long-term user behavior history; can be in the thousands.
- For each candidate item, quickly search the user's LastN records to find similar items.
- Convert LastN into TopK, then feed into the attention layer.
- SIM reduces computation (from to ).
Step 1: Search
-
Method 1: Hard Search
- Filter LastN items to keep only those with the same category as the candidate item.
- Simple, fast, requires no training.
-
Method 2: Soft Search
- Embed items to get vectors.
- Use the candidate item vector as a query and perform -nearest neighbor search, keeping the nearest items in LastN.
- Better performance, more complex to implement.
Step 2: Attention Mechanism
Using Temporal Information
- Let be the time elapsed since the user interacted with a LastN item.
- Discretize , then embed it to get vector d.
- Concatenate the two vectors to represent a LastN item:
- Vector x is the item embedding.
- Vector d is the time embedding.
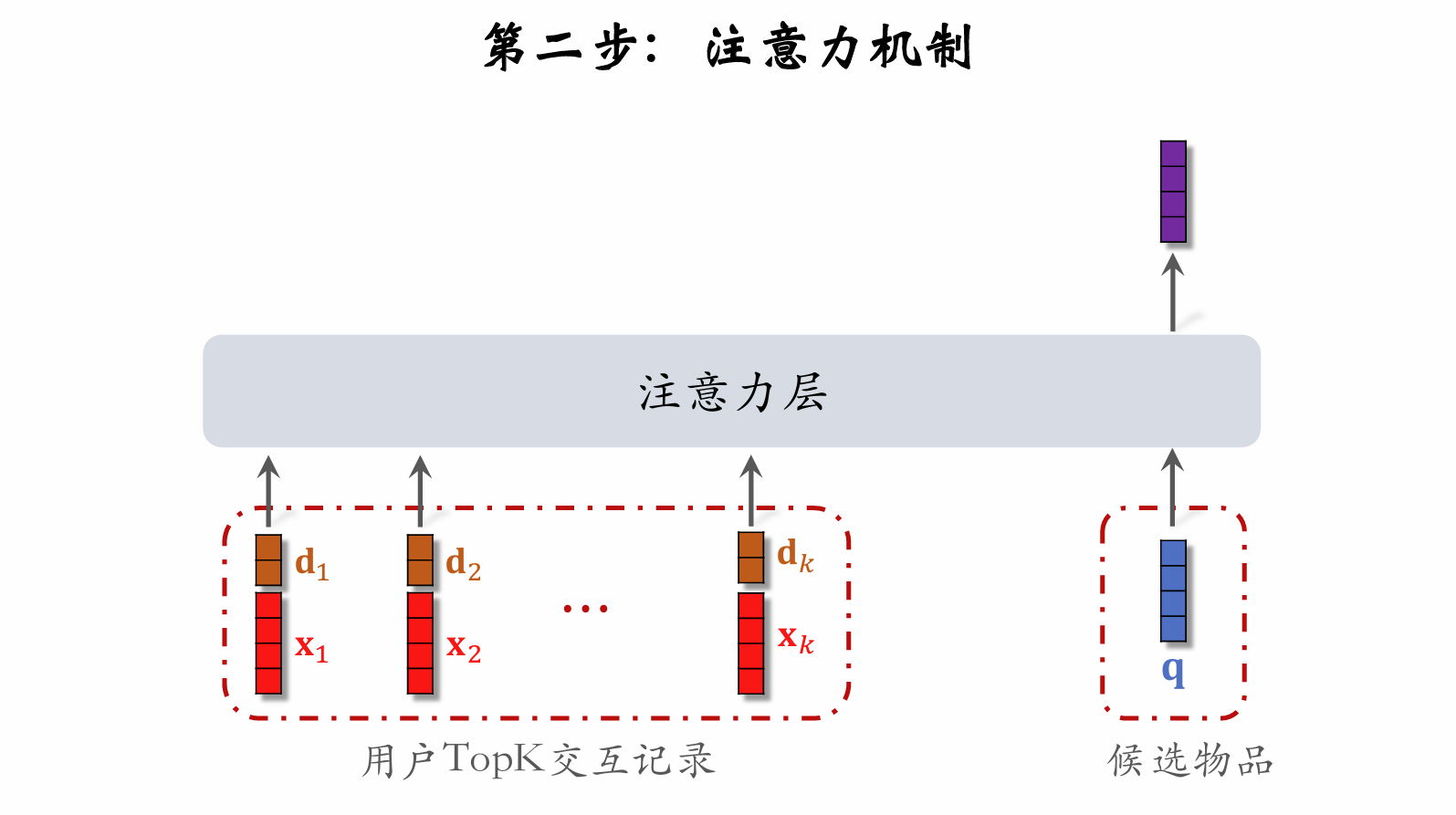
Why does SIM use temporal information?
- DIN has a short sequence, recording the user's recent behavior.
- SIM has a long sequence, recording the user's long-term behavior.
- The more distant the interaction in time, the less important it is.
Conclusions
- Long sequences (long-term interests) outperform short sequences (recent interests).
- Attention mechanism outperforms simple averaging.
- Soft search vs. Hard search? Depends on engineering infrastructure.
- Using temporal information provides improvement.
贡献者
最近更新
Involution Hell© 2026 byCommunityunderCC BY-NC-SA 4.0![]()
![]()
![]()
![]()