Wang Shusen Recommender Systems Study Notes — Improving Metrics
Wang Shusen Recommender Systems Study Notes — Improving Metrics
Methods for Improving Metrics
Methods for Improving Metrics
Evaluation Metrics for Recommender Systems
-
Daily Active Users () and retention are the most critical metrics.
-
The industry currently uses and most commonly to measure retention.
- If a user logs into the app today () and logs in on 4 of the next 7 days (), their for today () equals 4.
- Clearly and .
- Growth in typically indicates improved user experience. (Unless grows while falls.)
- If the app bans low-activity users, drops and grows.
-
Other core metrics: user session duration, total reads (i.e., total clicks), total impressions. These are less important than and retention.
- When session duration grows, typically grows.
- When session duration grows, reads and impressions may fall.
-
Non-core metrics: click-through rate, interaction rate, etc.
-
For UGC platforms, publishing volume and publishing penetration rate are also core metrics.
What Methods Are Available to Improve Metrics?
- Improve retrieval models and add new retrieval channels.
- Improve pre-ranking and full-ranking models.
- Improve diversity in retrieval, pre-ranking, and full ranking.
- Apply special treatment to new users, low-activity users, and other special groups.
- Leverage the three interaction behaviors: follows, shares, and comments.
Improving Metrics: Retrieval
Retrieval Models & Retrieval Channels
- Recommender systems have dozens of retrieval channels with a fixed total retrieval quota. A larger quota leads to better metrics but higher pre-ranking compute cost.
- Two-tower models () and item-to-item () are the two most important retrieval model classes, occupying the majority of the retrieval quota.
- Many niche models occupy very little quota. Adding certain retrieval models can improve core metrics while keeping total retrieval volume fixed.
- Multiple content pools exist: e.g., 30-day items, 1-day items, 6-hour items, new user high-quality pool, user-segment-specific pools.
- The same model can be used with multiple content pools, yielding multiple retrieval channels.
Improving Two-Tower Models
Direction 1: Optimize positive and negative samples.
- Simple positive samples: (user, item) pairs with clicks.
- Simple negative samples: randomly combined (user, item) pairs.
- Hard negative samples: (user, item) pairs ranked low by the ranking models.
Direction 2: Improve neural network architecture.
- Baseline: User tower and item tower are each fully connected networks, each outputting a single vector as user/item representation.
- Improvement: Replace fully connected networks in user and item towers with .
- Improvement: Use user behavior sequences () in the user tower.
- Improvement: Replace single-vector model with multi-vector model. (The standard two-tower model is also called a single-vector model.)
Direction 3: Improve model training methods.
- Baseline: Binary classification — teach the model to distinguish positive from negative samples.
- Improvement: Combine binary classification with in-batch negative sampling. (For in-batch negative sampling, apply debiasing.)
- Improvement: Apply self-supervised learning to improve embeddings for long-tail items.
Item-to-Item (I2I)
-
is a broad class of models that retrieve based on similar items.
-
The most common usage is ().
- User likes item (an item the user has interacted with historically).
- Find 's similar items (i.e., ).
- Recommend to .
-
How to compute item similarity?
-
Method 1: ItemCF and its variants.
- Some users like both items and ; then and are considered similar.
- , , , all share this underlying idea.
- Use all 4 models simultaneously online, each with a specific quota.
-
Method 2: Compute vector similarity based on item vector representations. (Both two-tower models and graph neural networks can compute item vector representations.)
Niche Retrieval Models
I2I-like Models
- U2U2I (): Given that user is similar to and likes item , recommend item to .
- U2A2I (): Given that user likes author and published item , recommend item to .
- U2A2A2I (): Given that user likes author , is similar to , and published item , recommend item to .
Summary: Improving Retrieval Models
- Two-tower models: Optimize positive/negative samples, improve neural network architecture, improve training methods.
- I2I models: Use and its variants simultaneously; compute item similarity using item vector representations.
- Add niche retrieval models, such as , , , , etc.
- Adjust quotas across retrieval channels while keeping total retrieval volume fixed. (Different quotas can be set for different user segments.)
Improving Metrics: Ranking Models
Ranking Models
- Improving the full-ranking model
- Improving the pre-ranking model
- User behavior sequence modeling
- Online learning
- Aged model ("old soup model")
Improving the Full-Ranking Model
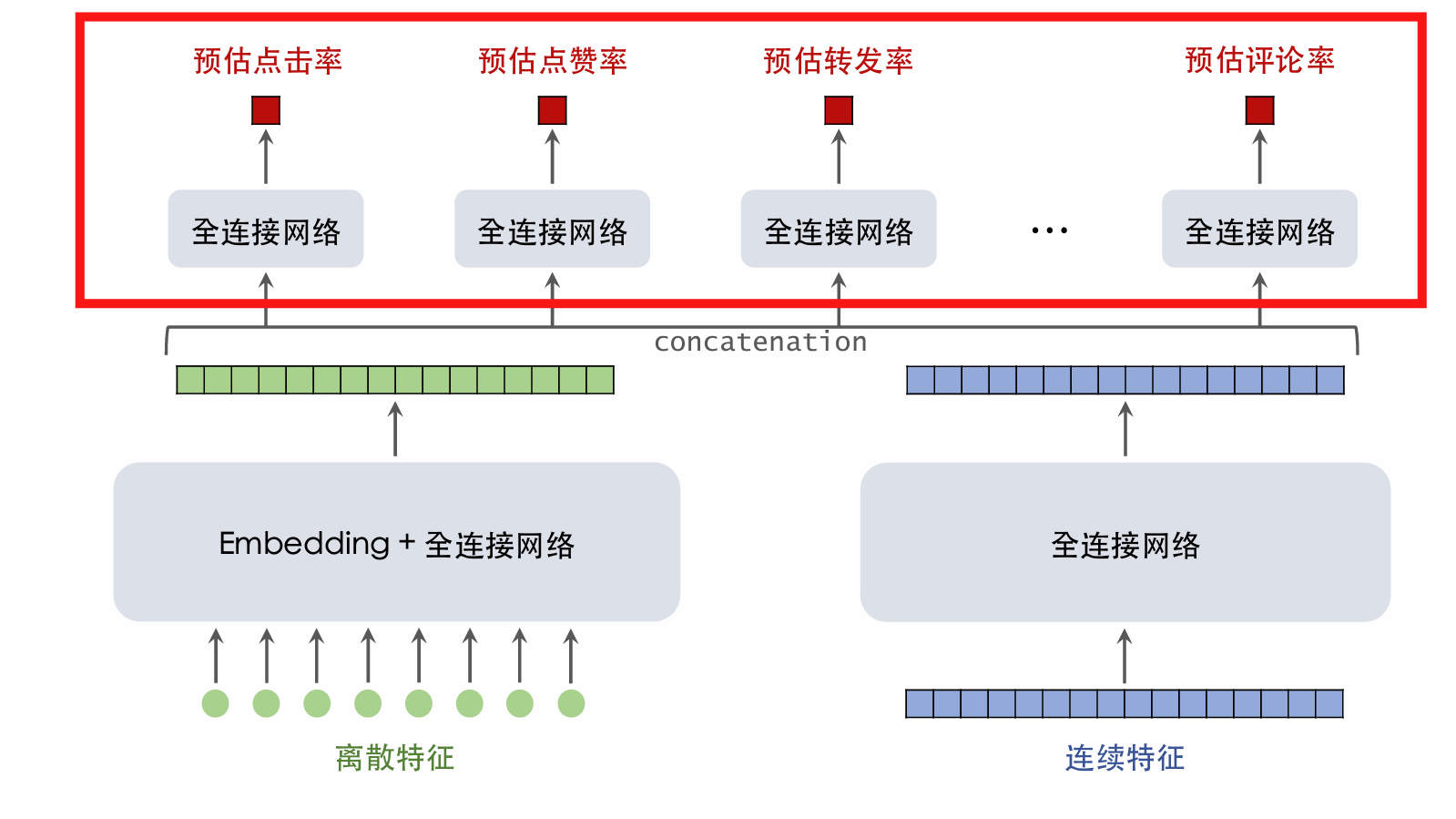
Full-Ranking Model: Backbone
- The backbone takes discrete and continuous features as input and outputs a vector, which serves as input to multi-objective estimation.
- Improvement 1: Widen and deepen the backbone for more compute and better predictions.
- Improvement 2: Automated feature crossing, e.g., [1] and [2].
- Improvement 3: Feature engineering, e.g., adding statistical features and multimodal content features.
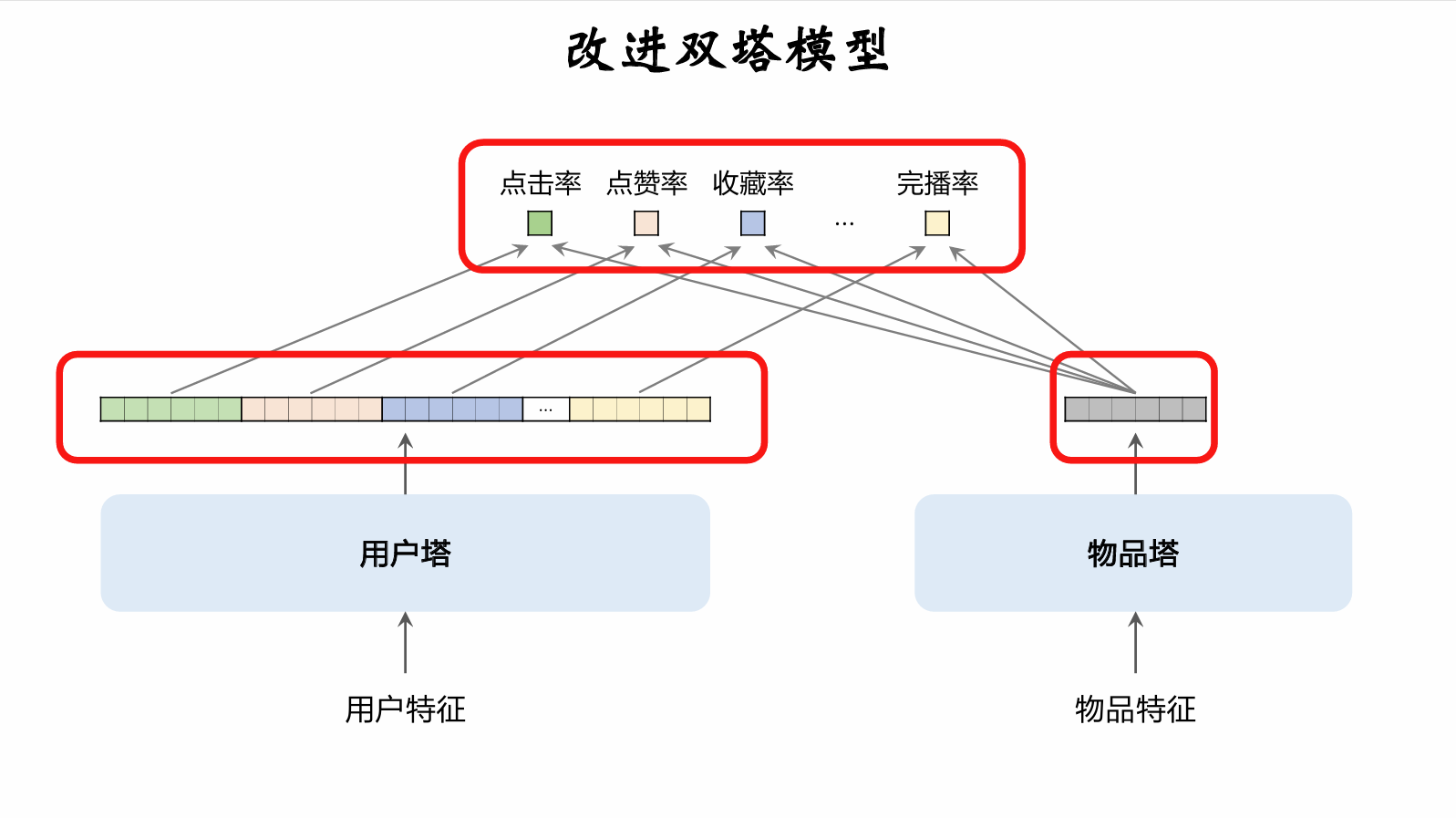
Full-Ranking Model: Multi-Objective Estimation
-
Based on the backbone output vector, simultaneously estimate multiple objectives such as click-through rate.
-
Improvement 1: Add new estimation targets and incorporate their estimated results into the fusion formula.
- Standard targets include CTR, like rate, favorite rate, share rate, comment rate, follow rate, completion rate...
- Discover additional targets, e.g., entering the comment section, liking comments written by others...
- Add new estimation targets to the fusion formula.
-
Improvement 2: Structures like and may help but often do not.
-
Improvement 3: Correcting may help, or may not.
Improving the Pre-Ranking Model
Pre-Ranking Model
- Pre-ranking scores 10× more items than full ranking; the pre-ranking model must be fast.
- Simple model: Multi-vector two-tower model, simultaneously estimating multiple targets like CTR.
- Complex model: Three-tower model performs well but is harder to implement in engineering.
Pre-ranking / Full-ranking Consistency Modeling
-
Distill full-ranking to train pre-ranking, making pre-ranking more consistent with full ranking.
-
Method 1: Pointwise distillation.
- Let be the user's true behavior; let be the full-ranking model's prediction.
- Use as the pre-ranking model's training target.
- Example:
- For CTR target: user clicked (), full-ranking predicts .
- Use as the pre-ranking's CTR target.
-
Method 2: Pairwise or listwise distillation.
- Given candidate items, rank them according to full-ranking predictions.
- Apply learning to rank (), training pre-ranking to fit item order (not values).
- Example:
- For items and , full-ranking predicts CTR .
- encourages pre-ranking predictions to satisfy ; otherwise a penalty is applied.
- typically uses pairwise logistic loss.
-
Advantage: Pre-ranking / full-ranking consistency modeling can improve core metrics.
-
Disadvantage: If full ranking has a bug and its predictions are biased, this pollutes pre-ranking training data.
User Behavior Sequence Modeling
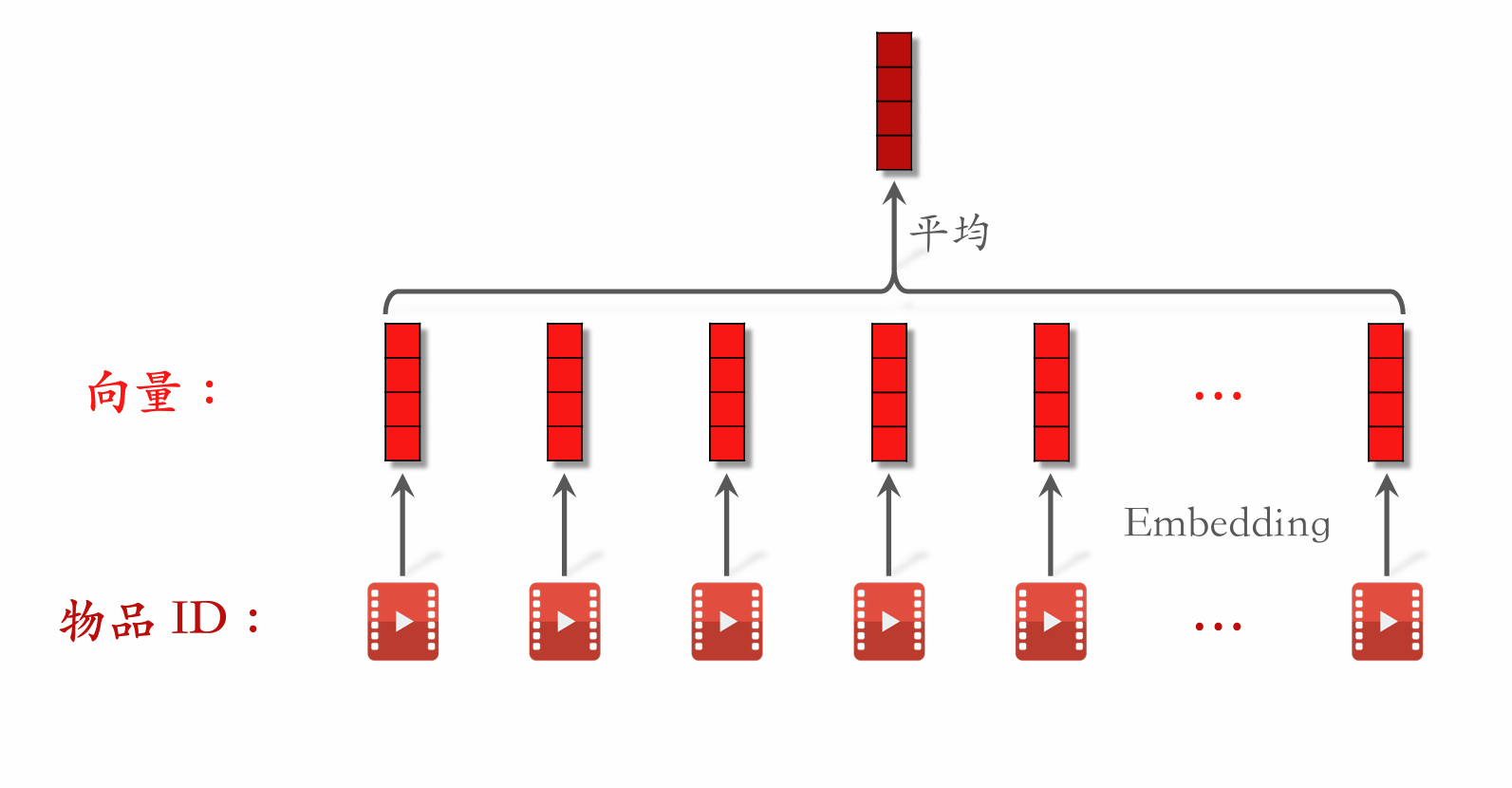
- The simplest method is to average item vectors as a user feature.
- uses an attention mechanism to compute a weighted average of item vectors.
- The industry is currently evolving along the direction: first filter items by category and other attributes, then use to compute a weighted average of the filtered item vectors.
User Behavior Sequence Modeling
-
Improvement 1: Increase sequence length for more accurate predictions, at the cost of higher compute and longer inference time.
-
Improvement 2: Filtering methods, e.g., by category or by item vector clustering.
- Offline: use a multimodal neural network to extract item content features and represent items as vectors.
- Offline: cluster item vectors into 1000 classes; each item has a cluster ID.
- Online during ranking: the user's behavior sequence has items. A candidate item has cluster ID 70; filter the items to keep only those with cluster ID 70. Only a few thousand of the items are retained.
- Multiple filtering methods are used simultaneously; take the union of filtered results.
-
Improvement 3: Use features beyond IDs for items in the user behavior sequence.
-
Summary: Evolve along the direction — keep the raw sequence as long as possible, then apply filtering to reduce sequence length, then feed filtered results into .
Online Learning
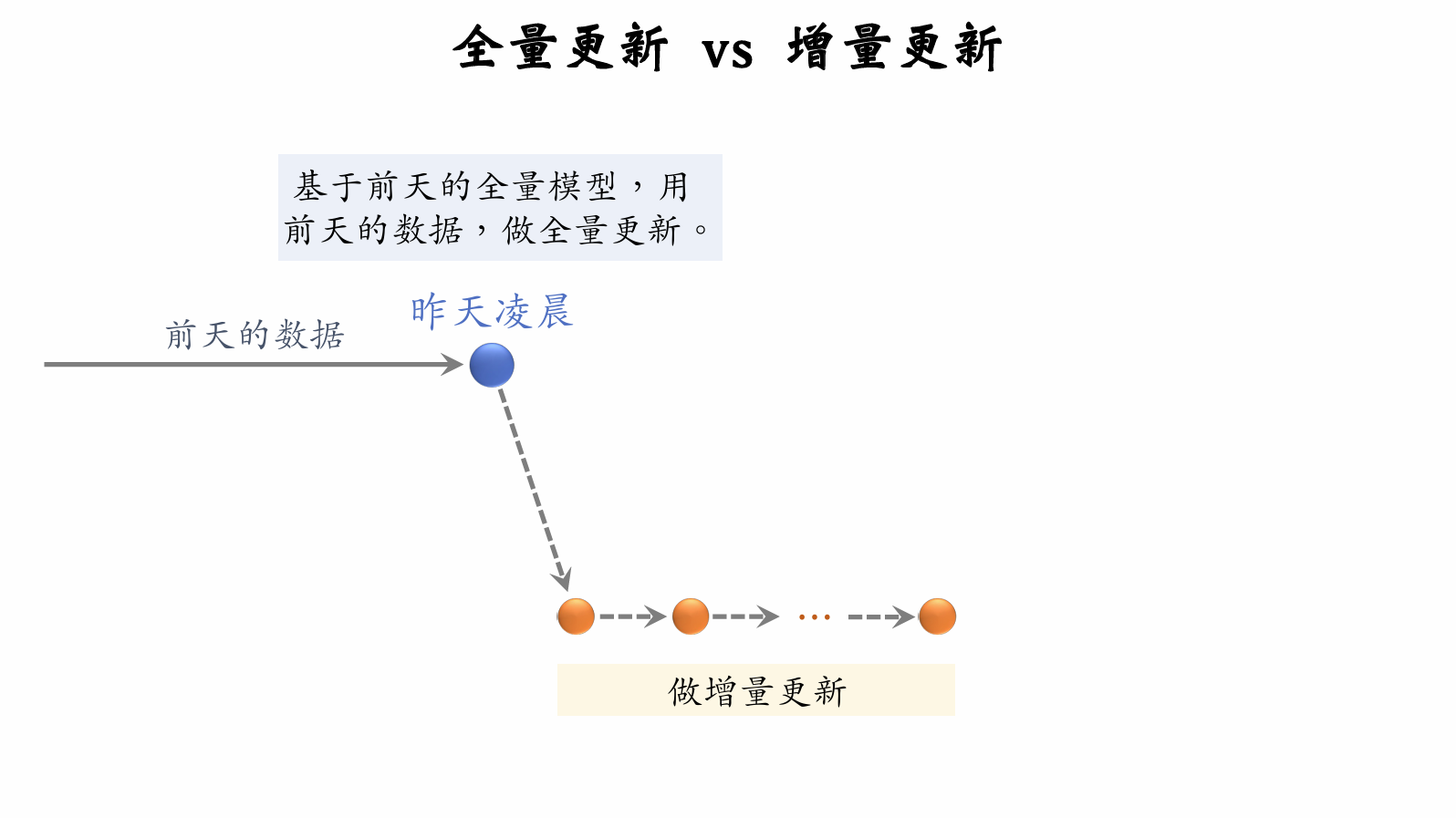
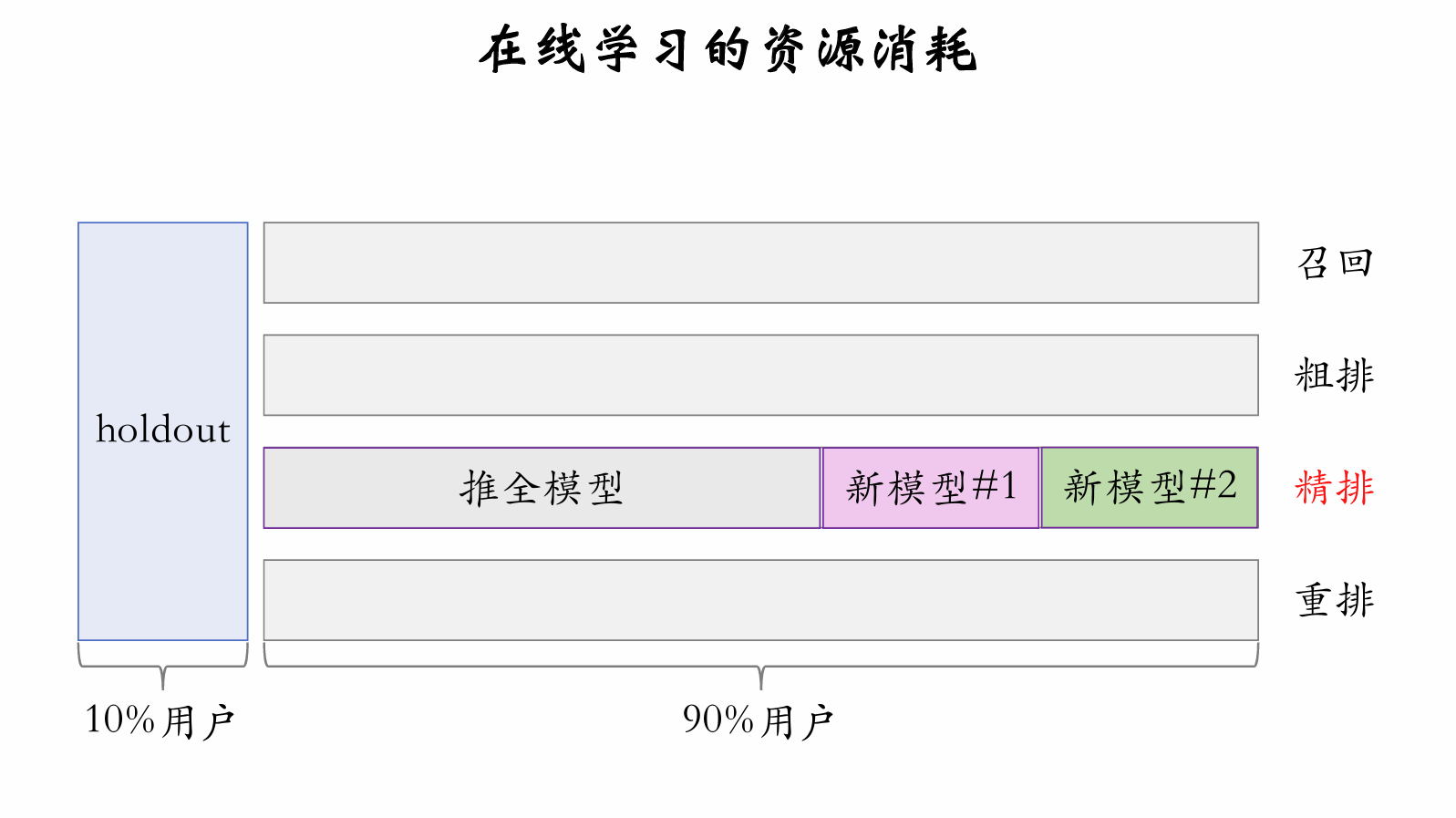
Resource Consumption of Online Learning
-
Requires both full batch updates at midnight and continuous incremental updates throughout the day.
-
Suppose online learning requires 10,000 to incrementally update a single full-ranking model. How much additional compute does the entire recommender system need for online learning?
-
For A/B testing, multiple different models run simultaneously online.
-
If there are models online, sets of online learning machines are needed.
-
Of models online: 1 is , 1 is fully rolled out, and are new models under test.
-
Each set of online learning machines has high cost, so is small, constraining model development iteration efficiency.
-
Online learning brings large metric improvements but constrains model development iteration efficiency.
Aged Model ("Old Soup Model")
- Train the model for 1 per day using newly generated data.
- Over time, the aged model becomes extremely well-trained and difficult to surpass.
- Improving the model architecture and retraining makes it very hard to catch up with the aged model...
- Problem 1: How to quickly determine if a new model architecture is better than the aged model? (No need to actually catch up with the online aged model — just determine which architecture is better.)
- For both new and old model architectures, randomly initialize fully connected layers.
- Embedding layers can be randomly initialized or reuse parameters from the trained aged model.
- Train both new and old models on days of data. (Train 1 from oldest to newest.)
- If the new model is significantly better, it is likely superior.
- Only compare which architecture is better, not actually catch up with the aged model.
- Problem 2: How to more quickly catch up with and surpass the online aged model? (Train the new model on only a few dozen days of data, yet match a model trained for hundreds of days.)
- Having already concluded the new model is likely better, train it on a few dozen days of data to catch up with the aged model quickly.
- Method 1: Reuse as many embedding layers from the aged model as possible; avoid random initialization of embedding layers. (Embedding layers encode "memory" of users and items and learn more slowly than fully connected layers.)
- Method 2: Use the aged model as to distill the new model. (True user behavior is ; aged model's prediction is ; use as the training target for the new model.)
Summary: Improving Ranking Models
- Full-ranking model: Improve model backbone (wider/deeper, feature crossing, feature engineering); improve multi-objective estimation (new targets, , ).
- Pre-ranking model: Three-tower model (replacing multi-vector two-tower); pre-ranking/full-ranking consistency modeling.
- User behavior sequence modeling: Evolve along the direction — extend sequence length, improve item filtering methods.
- Online learning: Large metric improvements, but reduces model iteration efficiency.
- Aged model constrains model iteration efficiency; requires special techniques.
Improving Metrics: Diversity
Ranking Diversity
Full-Ranking Diversity
-
Full-ranking stage: Rank item combining interest score and diversity score.
- : Interest score, i.e., fused score from CTR and other estimated targets.
- : Diversity score, i.e., difference between item and already selected items.
- Rank items using .
-
Commonly use MMR, DPP, and similar methods to compute diversity scores; full ranking uses a sliding window, pre-ranking does not.
- Full ranking determines final exposure; adjacent exposed items should have low similarity. So computing full-ranking diversity uses a sliding window.
- Pre-ranking should consider overall diversity, not just diversity within a sliding window.
-
Beyond diversity scores, full ranking uses diversification strategies to increase diversity.
- Category: After selecting item , the next 5 positions cannot share 's second-level category.
- Multimodal: Precompute multimodal content vector representations for items and cluster the full catalog into 1000 groups; during full ranking, after selecting item , the next 10 positions cannot belong to the same cluster as .
Pre-Ranking Diversity
- Pre-ranking scores 5000 items and selects 500 to send to full ranking.
- Improving diversity in both pre-ranking and full ranking can improve core recommender system metrics.
- Rank 5000 items by ; top 200 items go directly to full ranking.
- For the remaining 4800 items, compute interest score and diversity score for each item .
- Rank remaining 4800 items by ; top 300 go to full ranking.
Retrieval Diversity
Two-Tower Model: Adding Noise
- The user tower takes user features as input and outputs a user vector representation; then ANN search retrieves items with high vector similarity.
- During online retrieval (after computing the user vector, before ANN search), add random noise to the user vector.
- The narrower the user's interests (e.g., if the user's recent interactions cover only a few categories), the stronger the noise added.
- Adding noise makes retrieved items more diverse and can improve core recommender system metrics.
Two-Tower Model: Sampling User Behavior Sequences
- The user's most recent interactions (user behavior sequence) are input to the user tower.
- Keep the most recent items ().
- Randomly sample items from the remaining items (). (Can be uniform sampling or non-uniform sampling for category balance.)
- Use the resulting items as the user behavior sequence instead of all items.
- Why does sampling the user behavior sequence improve metrics?
- On one hand, injecting randomness makes retrieval results more diverse.
- On the other hand, can be very large, capturing interests from much further in the user's history.
U2I2I: Sampling User Behavior Sequences
-
In (), the first refers to one of the user's most recent interactions, called a seed item in .
-
items cover relatively few categories with category imbalance.
- The system has 200 categories; a given user's items may cover only 15 categories.
- The football category accounts for items; TV drama accounts for items; other categories account for fewer than each.
-
Apply non-uniform random sampling to select items from items, achieving category balance. (Concept and effect are similar to sampling user behavior sequences in two-tower models.)
-
Use the sampled items (instead of the original items) as seed items.
-
On one hand, categories are more balanced, improving diversity. On the other hand, can be larger, covering more categories.
Exploration Traffic
- 2% of each user's exposed items are non-personalized, used for interest exploration.
- Maintain a curated content pool of high-quality items with high interaction metrics. (Content pool can be segmented by user group, e.g., males aged 30–40.)
- Randomly sample a few items from the curated pool, skip ranking, and directly insert them into the final ranked results.
- Interest exploration negatively impacts core metrics in the short term but has positive long-term effects.
Summary: Improving Diversity
- Full ranking: Combine interest score and diversity score for ranking; apply rule-based diversification.
- Pre-ranking: Use only interest score to select some items; use combined interest score and diversity score to select additional items.
- Retrieval: Add noise to two-tower user vectors; apply non-uniform random sampling to user behavior sequences (applicable to both two-tower and U2I2I).
- Interest exploration: Reserve a small fraction of traffic for non-personalized recommendation.
Improving Metrics: Special Treatment for Special User Groups
Why Special Treatment for Special User Groups?
- New users and low-activity users have little behavioral history; personalized recommendation is inaccurate.
- New users and low-activity users are prone to churn; measures must be taken to improve retention.
- Special users' behavior (e.g., CTR, interaction rate) differs from mainstream users; models trained on all users' behavior are biased for special user groups.
Methods to Improve Metrics
- Build special content pools for retrieval targeting special user groups.
- Apply special ranking strategies to protect special users.
- Apply special ranking models to eliminate bias in model predictions.
Building Special Content Pools
Special Content Pools
- Why special content pools?
- New users and low-activity users have little behavioral history; personalized retrieval is inaccurate. (Since personalization is poor, at least ensure content quality is good.)
- Build special content pools tailored to specific groups to improve user satisfaction. For example, for middle-aged women who like commenting, build a comment-promoting content pool to meet these users' interaction needs.
How to Build Special Content Pools
- Method 1: Select high-quality items based on interaction counts and interaction rates received by items.
- Target segment: consider only a specific group, e.g., males aged 18–25 in second-tier cities.
- Build content pool: score items using this group's interaction counts and interaction rates; select top-scoring items for the content pool.
- The content pool has a weak personalization effect.
- Content pool is updated periodically: add new items, remove items with low interaction rates or expired relevance.
- This content pool only applies to that specific group.
- Method 2: Apply causal inference to assess items' contribution to group retention rate; select items based on their contribution.
Retrieval from Special Content Pools
-
Typically use two-tower models to retrieve from special content pools.
- Two-tower models are personalized.
- For new users, two-tower personalization is inaccurate.
- Compensate with high-quality content and weak personalization.
-
Additional training cost?
- For regular users, regardless of how many content pools there are, only one two-tower model is trained.
- For new users, since there is very little interaction history, a separate model must be trained.
-
Additional inference cost?
- Content pools update periodically, requiring ANN index updates.
- Online retrieval requires ANN search.
- Special content pools are much smaller (10–100× smaller than the full content pool), so additional compute is minimal.
Special Ranking Strategies
Differentiated Ranking Models
-
Special user groups behave differently from regular users. New users and low-activity users have CTR and interaction rates that are higher or lower than average.
-
Ranking models are dominated by mainstream users and make inaccurate predictions for special users.
- Models trained on all users' data make severely biased predictions for new users.
- If 90% of an app's users are female, models trained on all users' data are biased for male users.
-
Problem: For special users, how to make ranking model predictions more accurate?
-
Method 1: Large model + small model.
- Train a large model on all users' behavior; the large model's prediction fits user behavior .
- Train a small model on special users' behavior; the small model's prediction fits the large model's residual .
- For mainstream users, use only the large model's prediction .
- For special users, combine large and small model predictions: .
-
Method 2: Fuse multiple experts, similar to MMoE.
- Use a single model with multiple experts, each outputting a vector.
- Compute a weighted average of expert outputs.
- Compute weights based on user features.
- For new users, the model takes user features like recency and activity level as input and outputs weights for expert aggregation.
-
Method 3: After large model prediction, calibrate with a small model.
- Use the large model to estimate CTR and interaction rates.
- Feed user features and large model CTR/interaction rate estimates into a small model (e.g., GBDT).
- Train the small model on special user group data; small model output fits users' true behavior.
Wrong Approach
-
Use one ranking model per user group; recommendation system maintains multiple large models simultaneously.
- One main model; each user group has its own model.
- Update the main model nightly with all users' data.
- Based on the trained main model, retrain for 1 epoch on a specific group's data to create that group's model.
-
Short-term metric improvement; high maintenance cost, harmful long-term.
- Initially, the low-activity male user model has 0.2% higher AUC than the main model.
- After several main model iterations, AUC cumulatively improves by 0.5%.
- Too many special group models, unmaintained and unupdated long-term.
- If the low-activity male user model is taken offline and replaced with the main model, AUC for low-activity male users actually improves by 0.3%!
Summary: Special Treatment for Special User Groups
- Retrieval: For special user groups, build special content pools and add corresponding retrieval channels.
- Ranking strategy: Exclude low-quality items to protect new users and low-activity users; use special fusion formulas for special user groups.
- Ranking model: Combine large and small models, with the small model fitting the large model's residual; use a single model with multiple experts; calibrate large model predictions with a small model.
Improving Metrics: Leveraging Interaction Behaviors
Follows
Value of Follow Count for Retention
-
For a user, the more authors they follow, the stronger the platform's pull on them.
-
User retention rate () is positively correlated with number of authors followed ().
-
If a user's is small, the recommender system should encourage them to follow more authors.
-
How to use follow relationships to improve user retention?
-
Method 1: Use ranking strategies to increase follow counts.
- For user , the model estimates the follow rate for candidate item .
- Let user have already followed authors.
- Define a monotonically decreasing function : the more authors already followed, the smaller .
- Add to the ranking fusion formula to encourage follows. (If is small and is large, gives item a large bonus.)
-
Method 2: Build a follow-promoting content pool and retrieval channel.
- Items in this pool have high follow rates and can promote follows.
- If a user's follow count is small, apply this pool to that user.
- Retrieval quota can be fixed or negatively correlated with .
Value of Fan Count for Incentivizing Publishing
-
UGC platforms treat author publishing volume and publishing rate as core metrics, hoping authors publish more.
-
Items published by authors are pushed to users, generating likes, comments, follows, and other interactions.
-
Interactions (especially follows and comments) improve authors' publishing motivation.
-
The fewer fans an author has, the more each new fan boosts their publishing motivation.
-
Use ranking strategies to help low-fan new authors gain fans.
-
Let author 's fan count (number of followers) be .
-
Author 's item may be recommended to user ; the model estimates follow rate .
-
Define a monotonically decreasing function as weight; the more fans author has, the smaller .
-
Add to the ranking fusion formula to help low-fan authors gain fans.
Implicit Follow Relationships
- Retrieval channel U2A2I: user → author → item.
- Explicit follow relationships: User follows author ; recommend 's published items to . (CTR and interaction rate are typically higher than other retrieval channels.)
- Implicit follow relationships: User enjoys watching author 's items but has not followed .
- The number of implicitly followed authors far exceeds explicitly followed authors. Mining implicit follow relationships and building U2A2I retrieval channels can improve core recommender system metrics.
Shares
Promoting Shares (Share-back Traffic)
- A platform-A user shares an item to platform B, attracting off-platform traffic to A.
- Recommender systems that promote shares (also called share-back traffic) can improve DAU and consumption metrics.
- Does simply increasing share count work?
- The model estimates share rate ; the fusion formula contains a term , giving items with high share rates more exposure.
- Increasing weight promotes shares, attracting off-platform traffic, but negatively impacts CTR and other interaction rates.
KOL Modeling
-
Goal: Attract as much off-platform traffic as possible without harming clicks and other interactions.
-
Whose shares attract large off-platform traffic? Key Opinion Leaders (KOLs) on other platforms!
-
How to determine if a user on our platform is a KOL on other platforms?
-
Look at how much off-platform traffic their historical shares have driven.
-
Method 2: Build a share-promoting content pool and retrieval channel, effective for off-platform KOLs.
Comments
Comments Promote Publishing
- UGC platforms treat author publishing volume and publishing rate as core metrics, hoping authors publish more.
- Interactions like follows and comments can improve authors' publishing motivation.
- If a newly published item has not received many comments yet, boost its estimated comment rate so the item gains comments quickly.
- Add an extra term to the ranking fusion formula.
- : weight, negatively correlated with the number of comments item already has.
- : the model's estimated comment rate for recommending item to the user.
Other Value of Comments
-
Some users enjoy writing comments and interacting with authors and other commenters.
- Add a comment-promoting content pool for these users, giving them more opportunities to participate in discussions.
- Helps improve these users' retention.
-
Some users regularly leave high-quality comments (with high like counts on their comments).
- High-quality comments contribute to retention of authors and other users. (Authors and other users find such comments interesting or helpful.)
- Use ranking and retrieval strategies to encourage these users to comment more.
Summary: Leveraging Interaction Behaviors
-
Follows:
- Retention value (encourage new users to follow more authors, improving new user retention).
- Publishing value (help new authors gain more fans, improving author publishing motivation).
- Use implicit follow relationships for retrieval.
-
Shares: Identify which users are off-platform KOLs; leverage the value of their shares to attract off-platform traffic.
-
Comments:
- Publishing value (encourage new items to receive comments, improving author publishing motivation).
- Retention value (create more commenting opportunities for discussion-loving users).
- Encourage high-quality commenters to comment more.
贡献者
最近更新
Involution Hell© 2026 byCommunityunderCC BY-NC-SA 4.0![]()
![]()
![]()
![]()