Wang Shusen Recommender Systems Study Notes — Re-Ranking
Wang Shusen Recommender Systems Study Notes — Re-Ranking
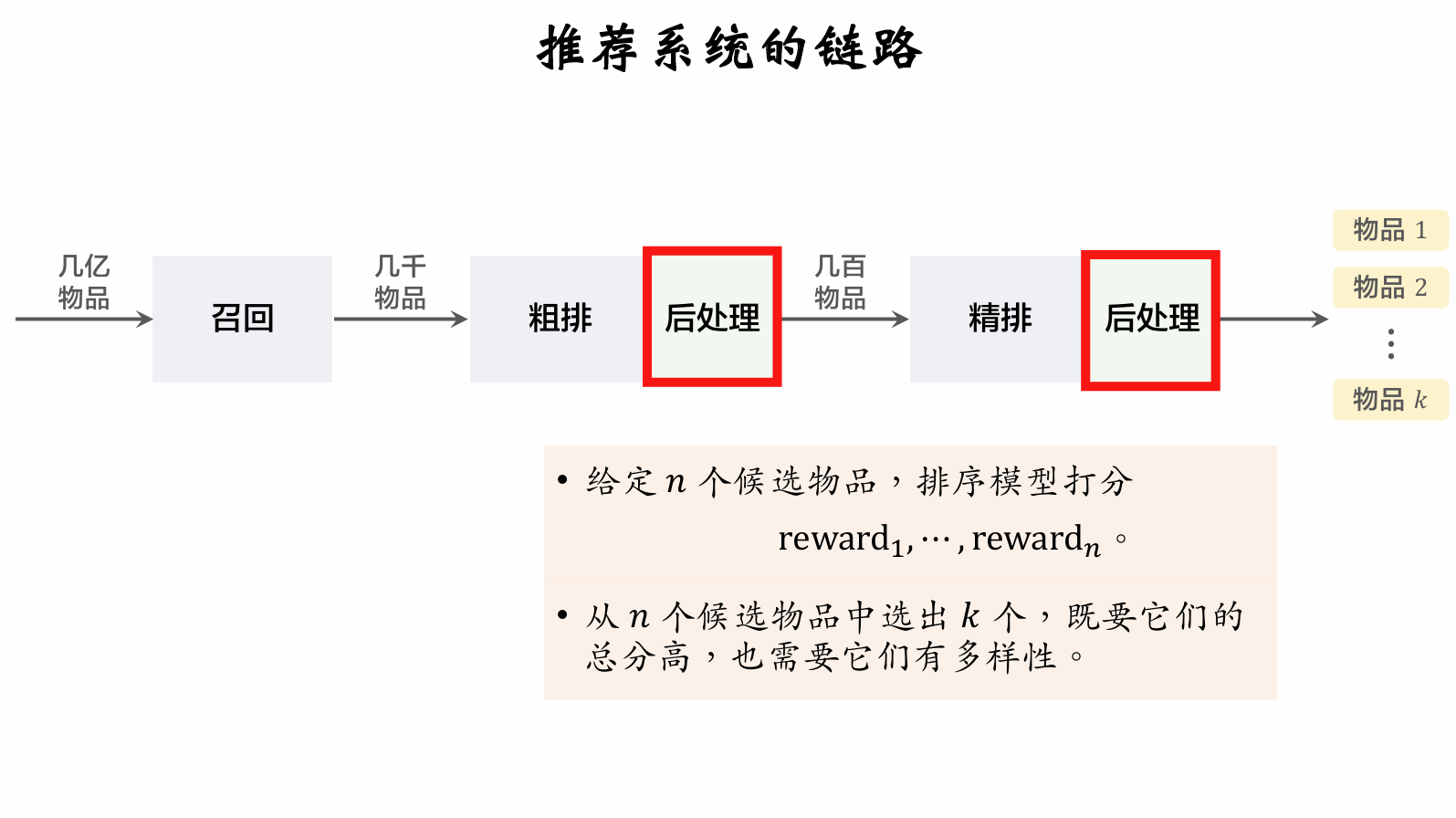
Re-Ranking
Diversity in Recommender Systems
Measuring Item Similarity
Similarity Measures
-
Based on item attribute tags.
- Category, brand, keywords...
-
Based on item vector representations.
- Item vectors learned by the retrieval two-tower model (not ideal).
- Content-based vector representations (preferred).
Attribute Tag-Based Similarity
- Item attribute tags: category, brand, keywords...
- Compute similarity based on first-level category, second-level category, and brand.
- Item : Beauty, Makeup, Chanel.
- Item : Beauty, Perfume, Chanel.
- Similarity: , , .
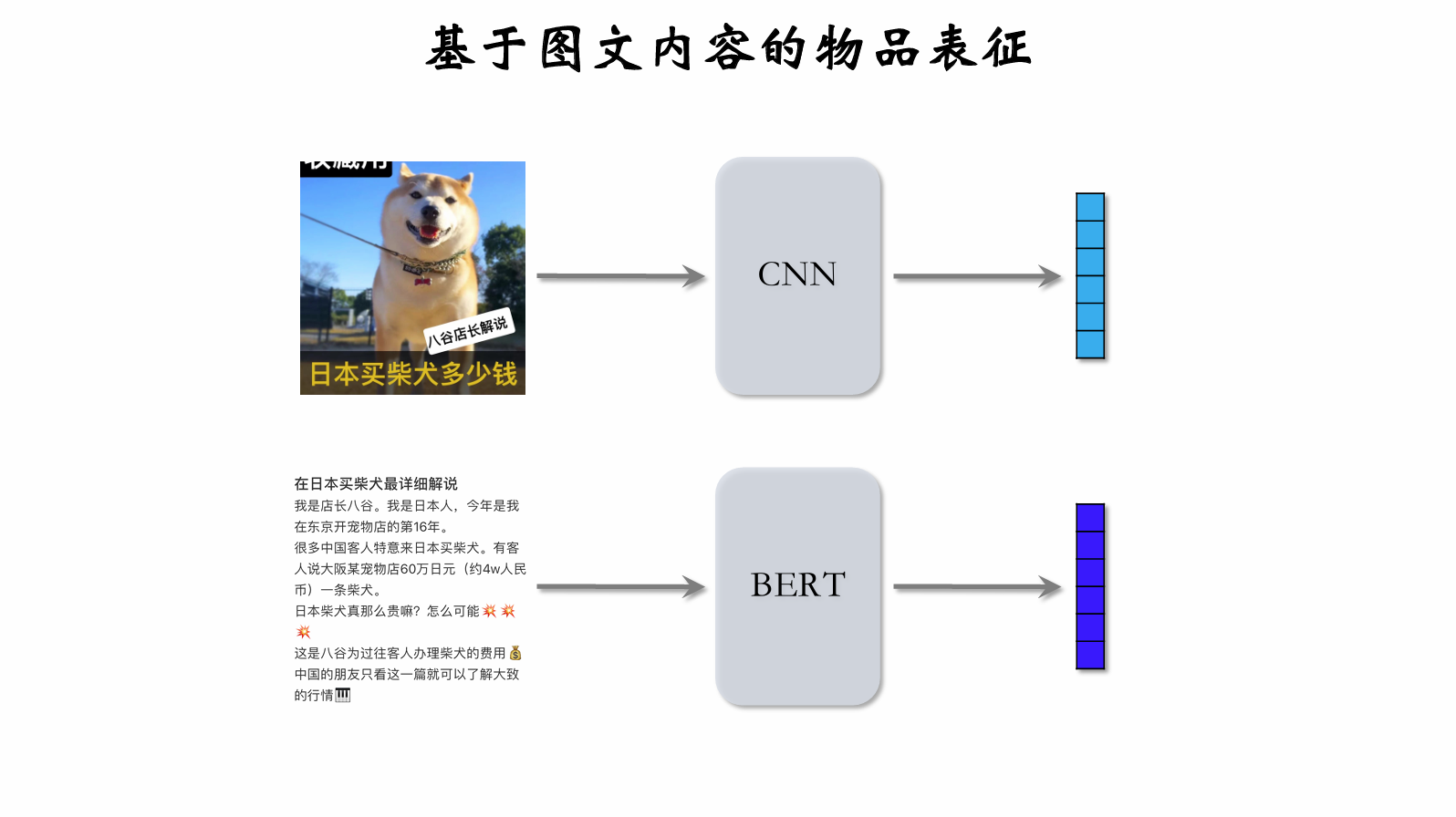
Content-based item representation can improve diversity.
CNN can process images to output feature vectors; BERT can process text to output feature vectors. The two vectors are then concatenated.
How to train CNN and BERT?
- CLIP is the currently recognized most effective pre-training method.
- Idea: For image–text pairs, predict whether the image and text match.
- Advantage: No manual annotation needed. Posts on Xiaohongshu naturally contain images + text, and most posts have matching image-text content.
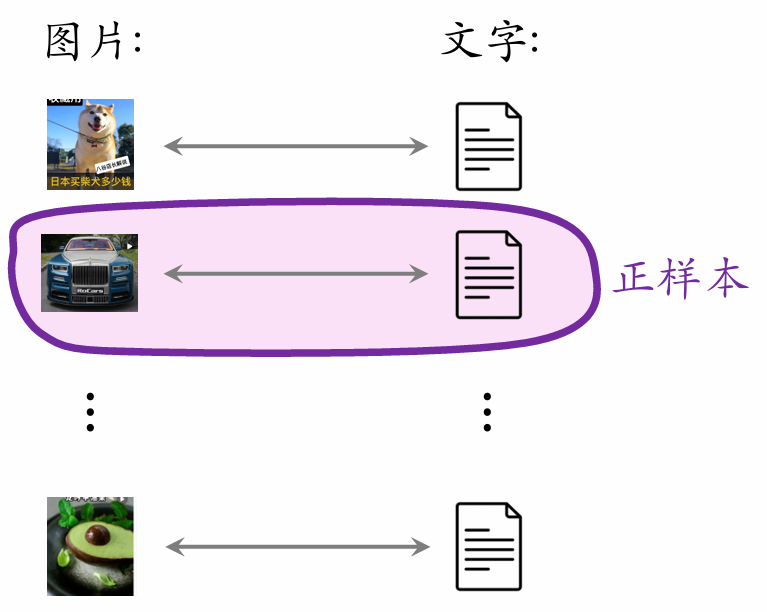
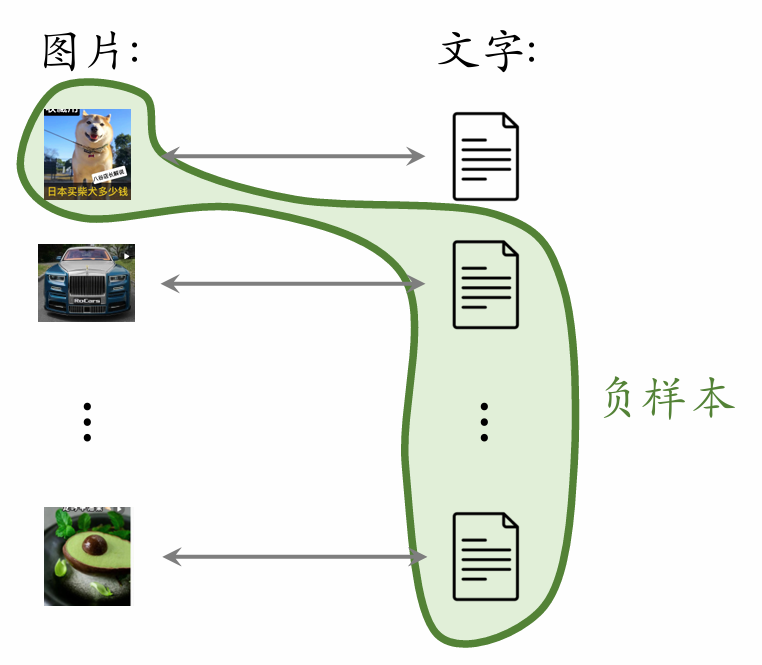
- A batch contains positive pairs.
- One image paired with texts forms negative samples.
- The batch contains negative pairs in total.
Methods for Improving Diversity
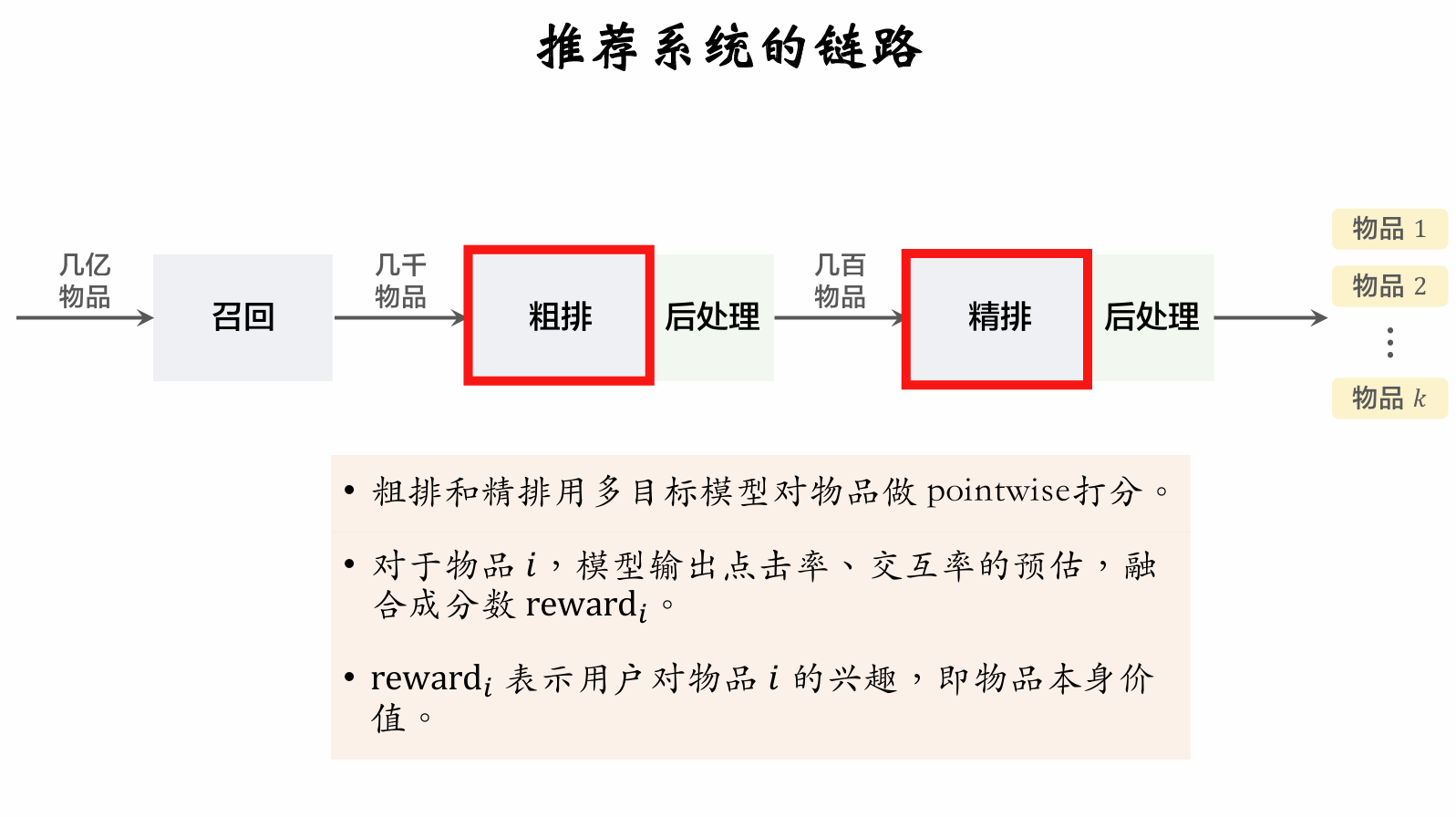
Post-processing in pre-ranking also requires diversity algorithms.
Post-processing in full ranking is also called re-ranking.
Maximal Marginal Relevance (MMR)
Diversity
- Full ranking scores candidate items; let the fused scores be
- Let the similarity between items and be .
- Select items from , requiring both high ranking scores and high diversity.
MMR Diversity Algorithm

-
Compute the Marginal Relevance score for each item in set :
-
is the item's full-ranking score; measures how similar the unselected item is to already selected items. A higher ranking score and lower similarity yield a higher MR score.
-
Maximal Marginal Relevance (MMR): Select the item with the highest MR score from unselected items:
MMR Diversity Algorithm
- Initialize selected items as the empty set; initialize unselected items as the full set .
- Select the item with the highest ranking score , move it from to .
- Repeat for rounds: a. Compute scores for all items in . b. Select the item with the highest score and move it from to .
Sliding Window
-
MMR:
-
As more items are selected (i.e., grows), it becomes harder to find item that is dissimilar to all items in .
-
Assuming has range : when is large, the diversity score is always approximately 1, causing MMR to break down.
-
Solution: Set a sliding window , e.g., the most recently selected 10 items, and replace in the MMR formula with .
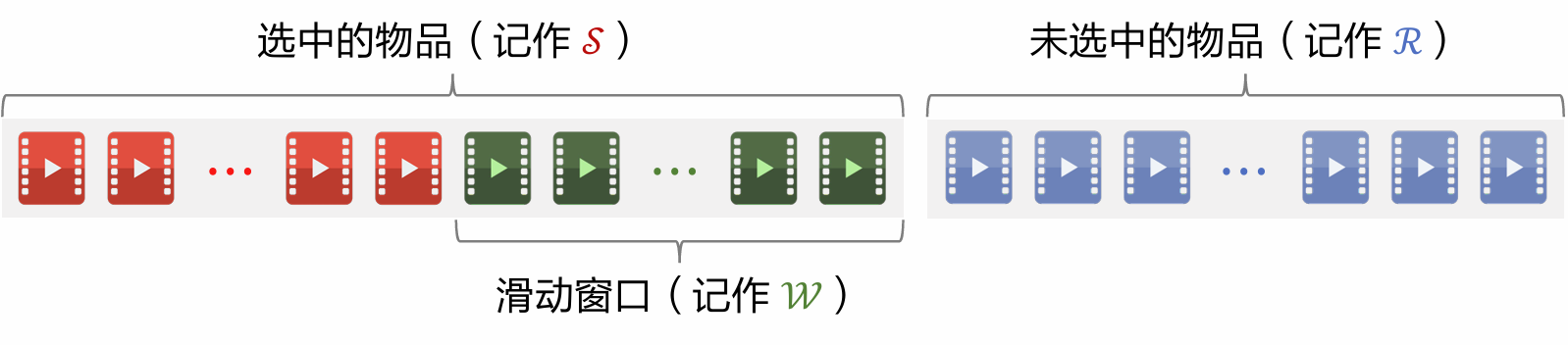
-
Standard MMR:
-
With sliding window:
Re-Ranking Rules
Re-Ranking Rules
Rule: At most consecutive posts of a certain type
- Xiaohongshu recommendation system items are divided into image-text posts and video posts.
- At most consecutive image-text posts; at most consecutive video posts.
- If positions through are all image-text posts, then position must be a video post.
Rule: At most 1 post of a certain type in every posts
- Promoted posts from operations have their ranking score multiplied by a factor greater than 1 (boost), helping them get more exposure.
- To prevent boost from harming user experience, limit to at most 1 promoted post per posts.
- If position is a promoted post, then positions through cannot be promoted posts.
Rule: At most posts of a certain type in the first posts
- The top posts receive the most visibility and matter most for user experience.
(Xiaohongshu's top 4 form the first screen) - Xiaohongshu recommendation system has posts with e-commerce cards; too many may hurt user experience.
- In the first posts, at most posts with e-commerce cards.
- In the first posts, at most post with e-commerce cards.
MMR + Re-Ranking Rules
-
MMR selects one item per round:
-
Re-ranking combines MMR with rules to maximize MR subject to rule constraints.
-
Each round, first use rules to exclude some items from , yielding subset .
-
Replace with in the MMR formula; selected items satisfy the rules.
DPP: Mathematical Foundations
Parallelepiped
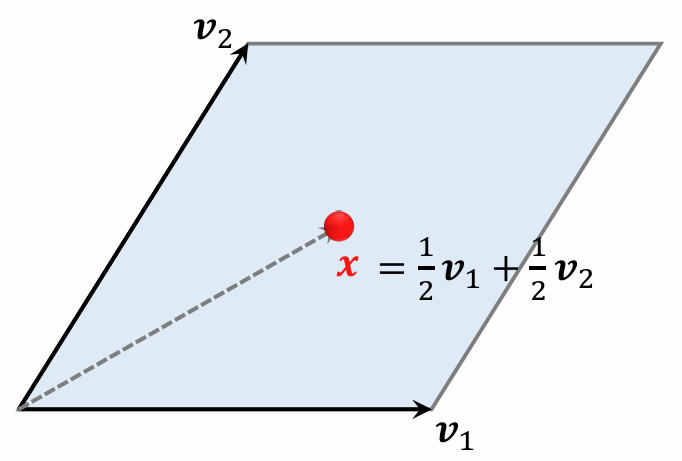
-
A parallelepiped in 2D space is a parallelogram.
-
Points in a parallelogram can be expressed as:
-
Coefficients and have range .
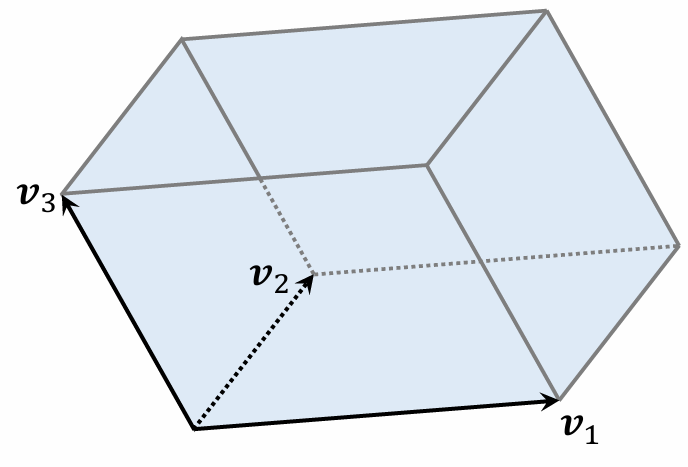
-
A parallelepiped in 3D space is a parallelepiped (3D).
-
Points in a parallelepiped can be expressed as:
-
Coefficients have range .
Parallelepiped
-
A set of vectors defines a -dimensional parallelepiped:
-
Requires ; for example, a -dimensional parallelogram in -dimensional space.
-
If are linearly dependent, then volume . (Example: vectors lying on a plane yield a parallelepiped with volume 0.)
Area of a Parallelogram
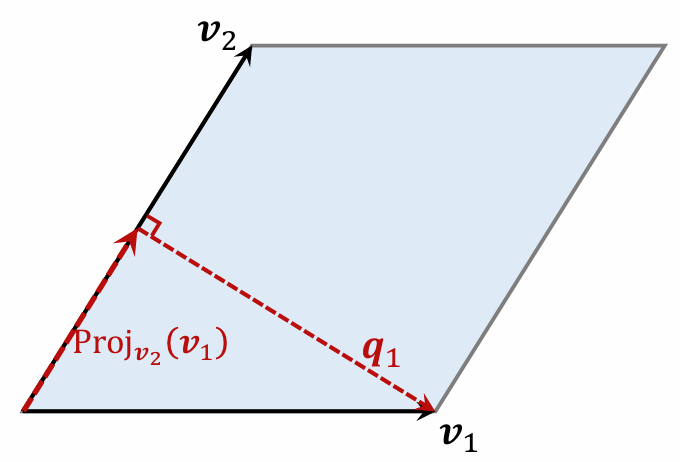
Using as the base, how to compute the height ?
-
Compute the projection of onto :
-
Compute
-
Property: base and height are orthogonal.
Volume of a Parallelepiped
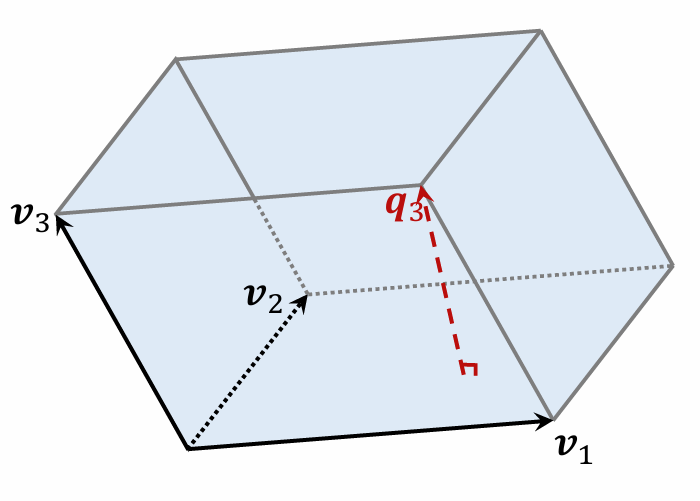
-
Volume = base area × .
-
Parallelogram is the base of parallelepiped .
-
Height is perpendicular to the base .
When is Volume Maximized/Minimized?
-
Let , , all be unit vectors.
-
When the three vectors are orthogonal, the parallelepiped is a cube; volume is maximized at .
-
When the three vectors are linearly dependent, volume is minimized at .
Measuring Item Diversity
-
Given items, represent them as unit vectors . ()
-
Use parallelepiped volume to measure item diversity; volume ranges between and .
-
If are mutually orthogonal (high diversity), volume is maximized at .
-
If are linearly dependent (low diversity), volume is minimized at .
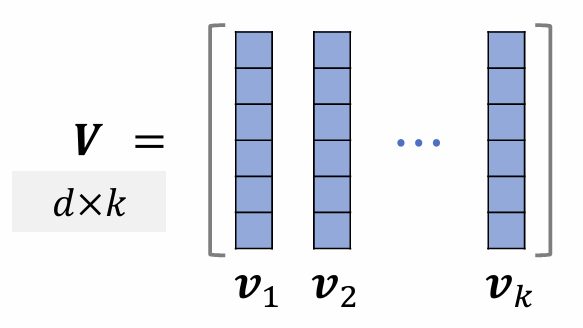
-
Given items represented as unit vectors . ()
-
Arrange them as columns of matrix .
-
With , determinant and volume satisfy:
-
Therefore, the determinant can be used to measure the diversity of vectors .
DPP: Diversity Algorithm
Diversity Problem
-
Full ranking scores items: .
-
Vector representations of items: .
-
Select items from to form set :
- High value: sum of scores should be maximized.
- High diversity: volume of parallelepiped formed by vectors in should be maximized.
-
Let the item vectors in form the columns of matrix .
-
Use these vectors as edges to form parallelepiped .
-
Volume can measure the diversity of items in .
-
With , determinant and volume satisfy:
Determinantal Point Process (DPP)
-
DPP is a classical statistical machine learning method:
-
Hulu's paper applies DPP to recommender systems:
-
DPP applied to recommender systems:
-
Let be an matrix with element equal to .
-
Given vectors , computing takes time.
-
is a submatrix of . If , then is an element of .
-
DPP applied to recommender systems:
-
DPP is a combinatorial optimization problem: select a subset of size from .
-
Let denote selected items and unselected items; solve greedily:
Solving DPP
Brute Force Algorithm
-
Greedy algorithm:
-
Complexity analysis:
-
For a single , computing the determinant of takes time.
-
For all , computing determinants takes time.
-
The above must be solved times to select items. Using brute-force determinant computation, total time complexity is:
-
-
Total time complexity of brute-force algorithm:
Hulu's Fast Algorithm
-
Hulu's paper designs a numerical algorithm that selects items from in only time.
-
Given vectors , computing takes time.
-
Compute all determinants in time using Cholesky decomposition.
-
Cholesky decomposition , where is a lower triangular matrix (all elements above the diagonal are zero).
-
Cholesky decomposition enables computing the determinant of :
-
The determinant of lower triangular matrix equals the product of diagonal elements.
-
The determinant of is:
-
-
Given , one can quickly derive the Cholesky decomposition of all , thus quickly computing all determinants .
-
Greedy algorithm:
-
Initialization: contains only one item; is a matrix.
-
Each round:
- Based on from the previous round, quickly derive the Cholesky decomposition of ().
- From this, compute .
DPP Extensions
Sliding Window
-
Let denote selected items and unselected items; DPP greedy solution:
-
As set grows, similar items accumulate; item vectors tend toward linear dependence.
-
Determinant collapses to zero; its logarithm approaches negative infinity.
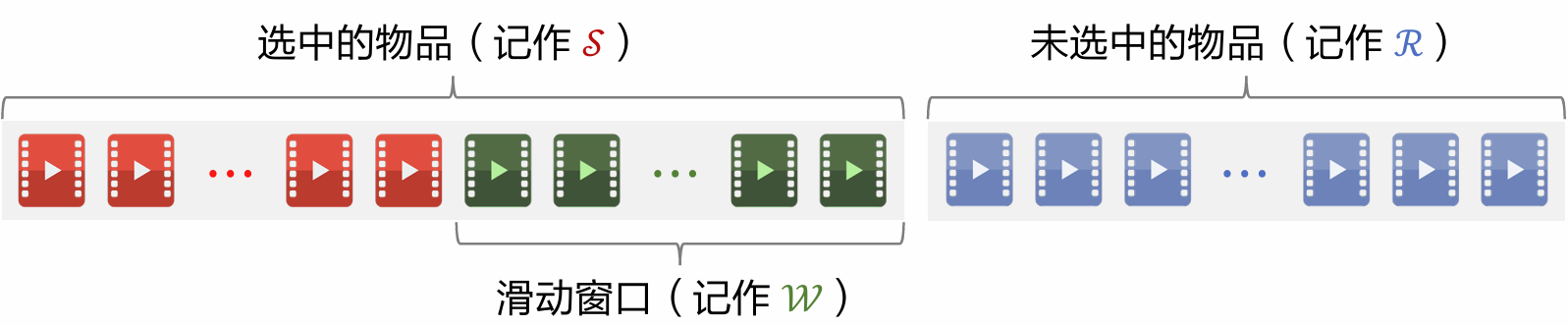
-
Greedy algorithm:
-
With sliding window:
Rule Constraints
-
Each round of the greedy algorithm selects one item from :
-
Many rule constraints exist, e.g., at most 5 consecutive video posts (if 5 video posts have already appeared consecutively, the next must be an image-text post).
-
Use rules to exclude some items from , yielding subset , then solve:
贡献者
最近更新
Involution Hell© 2026 byCommunityunderCC BY-NC-SA 4.0![]()
![]()
![]()
![]()