Handwritten Thread Pool
Thread Pool
The code below uses the single-queue
BlockingQueue. When using the double-queue version, replace allBlockingQueuewithBlockingQueuePro.
Interface
Constructor: Initializes the blocking queue with a unique_ptr, creates threads_num threads, and binds each to the Worker function. (All Workers block inside Pop() at this point.)
Post: Submits a task to the thread pool.
Destructor: Wakes up all consumer threads. Workers that find no tasks exit. This has nothing to do with producers.
#pragma once
#include <thread>
#include <functional>
#include <vector>
template <typename T>
class BlockingQueue;
class ThreadPool {
public:
// initialize the thread pool
explicit ThreadPool(int threads_num);
// stop the thread pool
~ThreadPool();
// submit a task to the thread pool
void Post(std::function<void()> task);
private:
// the loop function each thread runs
void Worker();
// task queue
std::unique_ptr<BlockingQueue<std::function<void()>>> task_queue_;
// holds all thread objects; each thread is bound to Worker()
std::vector<std::thread> workers_;
};#include "blockingqueue.h"
#include <memory>
#include "threadpool.h"
// Creates a blocking queue and spawns threads_num threads, each bound to Worker().
ThreadPool::ThreadPool(int threads_num) {
task_queue_ = std::make_unique<BlockingQueue<std::function<void()>>>();
for (size_t i = 0; i < threads_num; ++i) {
workers_.emplace_back([this] {Worker();});
// The lambda [this] { Worker(); } captures this, so each thread can call the current object's Worker.
}
}
// Stop the thread pool
// Cancel the queue and wake up all blocked threads
ThreadPool::~ThreadPool() {
task_queue_->Cancel();
for(auto &worker : workers_) {
if (worker.joinable())
worker.join();
}
}
// Submit a task
void ThreadPool::Post(std::function<void()> task) {
task_queue_->Push(task);
}
// Fetch a task from task_queue_ and execute it
void ThreadPool::Worker() {
while (true) {
std::function<void()> task;
// blocking is implemented inside Pop
if (!task_queue_->Pop(task)) {
break;
}
task();
}
}Blocking Queue (Single-Queue Version)
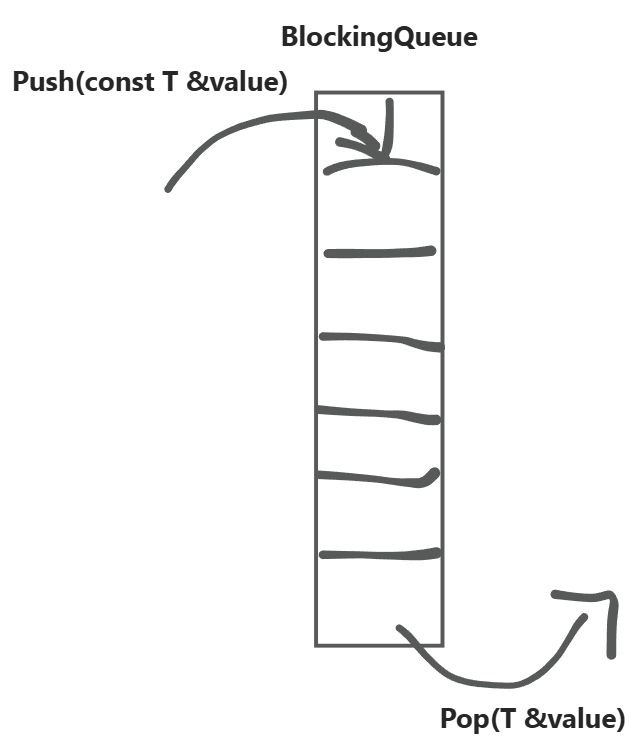
Single-queue maintenance:
nonblock_(bool): non-blocking flag. Whentrue, the queue does not block. Default is blocking (false) at construction.queue_(std::queue<T>): the underlying storage container.mutex_(std::mutex): mutex for thread-safe access.not_empty_(std::condition_variable): used for producer-consumer synchronization.
template <typename T>
class BlockingQueue {
public:
BlockingQueue(bool nonblock = false) : nonblock_(nonblock) { }
// enqueue
void Push(const T &value) {
// lock_guard automatically locks/unlocks (locks on construction, unlocks on destruction)
std::lock_guard<std::mutex> lock(mutex_);
// push element into queue
queue_.push(value);
// notify one waiting thread: the queue is not empty, a task is available
not_empty_.notify_one();
}
// normal pop: element is returned
// exceptional pop: no element returned
bool Pop(T &value) {
// lock — if already locked by another thread, this thread blocks here
// condition_variable::wait requires unique_lock
std::unique_lock<std::mutex> lock(mutex_);
// The main purpose of this line is to ensure safe dequeue.
// We only proceed when the queue is non-empty.
// But what if we only check queue emptiness and Cancel() is called?
// After Cancel(), we want consumers to exit, but they'd still block here
// because they don't know whether to stop.
// So we use nonblock_ to signal consumers to stop.
//
// Proceed when: queue is non-empty OR Cancel() has been called
// -> predicate is true -> continue
// Block when: queue is empty AND Cancel() has NOT been called
// -> predicate is false -> auto-unlock mutex, yield CPU, block here
not_empty_.wait(lock, [this]{ return !queue_.empty() || nonblock_; });
if (queue_.empty()) return false; // consumer thread exits
value = queue_.front();
queue_.pop();
return true;
}
// unblock all threads waiting on this queue
void Cancel() {
// auto lock/unlock
std::lock_guard<std::mutex> lock(mutex_);
// tell consumers to stop
nonblock_ = true;
// wake up all threads blocked in wait (each woken thread re-evaluates the predicate)
not_empty_.notify_all();
}
private:
bool nonblock_;
std::queue<T> queue_;
std::mutex mutex_;
std::condition_variable not_empty_;
};Blocking Queue (Double-Queue Version)
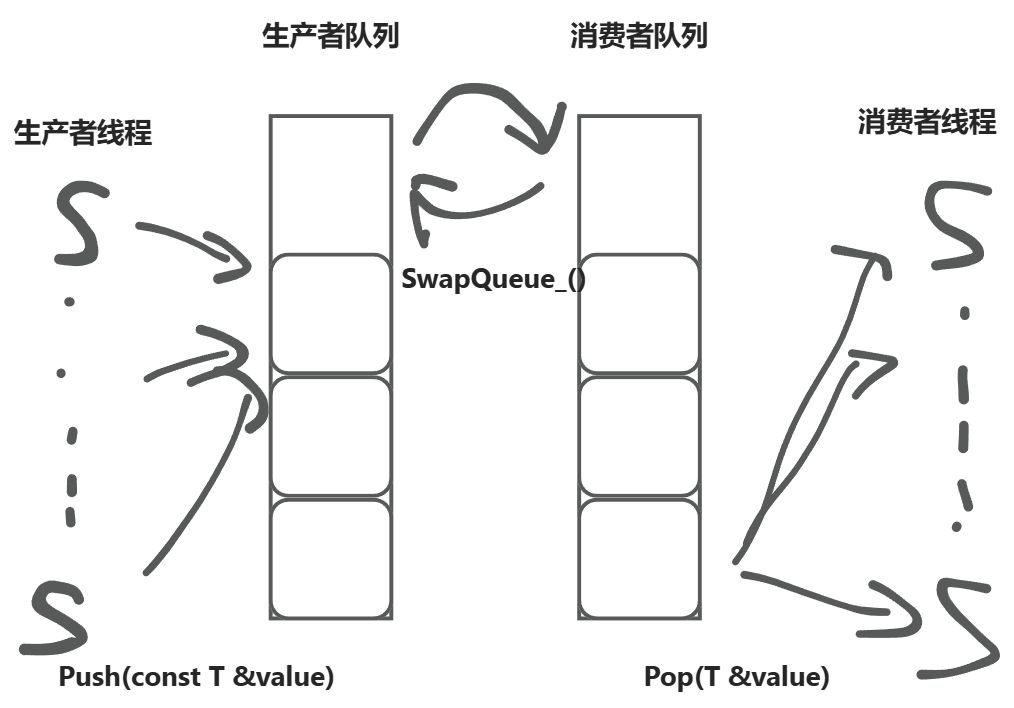
In the single-queue version, both producers and consumers compete for the same lock.
Double-queue design:
prod_queue_: the queue producers write to (protected byprod_mutex_).cons_queue_: the queue consumers read from (protected bycons_mutex_).- When the consumer queue is empty,
SwapQueue_()swaps the two queues, enabling batch transfer.
Benefits:
- Reduced lock contention: producers and consumers mostly do not compete for the same lock.
- Higher throughput: a single swap lets consumers retrieve data in bulk, reducing frequent locking.
template <typename T>
class BlockingQueuePro {
public:
BlockingQueuePro(bool nonblock = false) : nonblock_(nonblock) {}
void Push(const T &value) {
std::lock_guard<std::mutex> lock(prod_mutex_);
prod_queue_.push(value);
not_empty_.notify_one();
}
bool Pop(T &value) {
std::unique_lock<std::mutex> lock(cons_mutex_);
// auto-trigger swap when consumer queue is empty; if still empty after swap, return false
// no need for .wait here
if (cons_queue_.empty() && SwapQueue_() == 0) {
return false;
}
value = cons_queue_.front();
cons_queue_.pop();
return true;
}
void Cancel() {
std::lock_guard<std::mutex> lock(prod_mutex_);
nonblock_ = true;
not_empty_.notify_all();
}
private:
int SwapQueue_() {
std::unique_lock<std::mutex> lock(prod_mutex_);
// block when producer queue is empty and not cancelled
// proceed when cancelled regardless of queue state
not_empty_.wait(lock, [this] {return !prod_queue_.empty() || nonblock_; });
std::swap(prod_queue_, cons_queue_);
// return the number of items now in the consumer queue
// =0 only when producer queue was empty and cancellation was signalled
return cons_queue_.size();
}
bool nonblock_;
std::queue<T> prod_queue_;
std::queue<T> cons_queue_;
std::mutex prod_mutex_;
std::mutex cons_mutex_;
std::condition_variable not_empty_;
};Benchmark
The double-queue version is theoretically faster due to reduced lock contention. The experiment below confirms this.
Setup: 4 producer threads, each submitting 25,000 tasks (each task runs a 1,000-iteration loop). The consumer thread count equals the optimal thread count for the current CPU (std::thread::hardware_concurrency()). In this WSL environment, that is 16.
Both single (single-queue) and double (double-queue) versions are benchmarked, outputting total elapsed time and QPS.
std::atomic<int> task_counter{0};
int main() {
const int num_producers = 4;
const int num_tasks_per_producer = 25000; // 100,000 tasks total
const int num_threads_in_pool = std::thread::hardware_concurrency();
// For testing, the single and double versions are subclasses of ThreadPoolBase
// See appendix for implementation details
ThreadPoolSingle pool(num_threads_in_pool);
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> producers;
// 4 producers start working
for (int i = 0; i < num_producers; ++i) {
producers.emplace_back(Producer, std::ref(pool), i, num_tasks_per_producer);
}
for (auto& p : producers) {
p.join();
}
// main thread busy-waits; using std::condition_variable to wait for wakeup would be more efficient
while (task_counter < num_producers * num_tasks_per_producer) {
std::this_thread::sleep_for(std::chrono::milliseconds(50));
}
auto end = std::chrono::high_resolution_clock::now();
double elapsed = std::chrono::duration<double>(end - start).count();
int total_tasks = num_producers * num_tasks_per_producer;
std::cout << "[Single Queue] Total: " << total_tasks
<< " tasks. Time: " << elapsed
<< " seconds. QPS = " << total_tasks / elapsed << std::endl;
}void Task(int id) {
volatile long sum = 0;
for (int i = 0; i < 1000; ++i) {
sum += i;
}
task_counter++;
}
void Producer(ThreadPoolSingle& pool, int producer_id, int num_tasks) {
for (int i = 0; i < num_tasks; ++i) {
int task_id = producer_id * 100000 + i;
pool.Post([task_id]() { Task(task_id); });
}
}Results:

After reducing task count and main-thread poll interval by 10x (tasks per producer: 2,500, poll interval: 5 ms) — the original completed too fast and the main thread wait time distorted results:

Averaging across runs would be more rigorous, but the gap is large enough that measurement error does not affect the conclusion.
Appendix
Modified single-queue and double-queue versions
#pragma once
#include <thread>
#include <functional>
#include <vector>
#include "blockingqueue.h"
#include "blockingqueuepro.h"
// forward declarations
// blockingqueue can only be used as pointer or reference
// template <typename T>
// class BlockingQueue;
// template <typename T>
// class BlockingQueuePro;
// class ThreadPool {
// public:
// // initialize the thread pool
// explicit ThreadPool(int threads_num);
// // stop the thread pool
// ~ThreadPool();
// // submit a task to the thread pool
// void Post(std::function<void()> task);
// private:
// void Worker();
// std::unique_ptr<BlockingQueue<std::function<void()>>> task_queue_;
// std::vector<std::thread> workers_;
// };
class ThreadPoolBase {
public:
explicit ThreadPoolBase(int threads_num) : threads_num_(threads_num) {}
virtual ~ThreadPoolBase() = default;
virtual void Post(std::function<void()> task) = 0;
protected:
int threads_num_;
std::vector<std::thread> workers_;
};
class ThreadPoolSingle : public ThreadPoolBase {
public:
explicit ThreadPoolSingle(int threads_num)
: ThreadPoolBase(threads_num),
task_queue_(std::make_unique<BlockingQueue<std::function<void()>>>()) {
for (int i = 0; i < threads_num_; ++i) {
workers_.emplace_back([this] { Worker(); });
}
}
~ThreadPoolSingle() {
task_queue_->Cancel();
for (auto &w : workers_) {
if (w.joinable()) w.join();
}
}
void Post(std::function<void()> task) override {
task_queue_->Push(task);
}
private:
void Worker() {
while (true) {
std::function<void()> task;
if (!task_queue_->Pop(task)) break;
task();
}
}
std::unique_ptr<BlockingQueue<std::function<void()>>> task_queue_;
};
class ThreadPoolDouble : public ThreadPoolBase {
public:
explicit ThreadPoolDouble(int threads_num)
: ThreadPoolBase(threads_num),
task_queue_(std::make_unique<BlockingQueuePro<std::function<void()>>>()) {
for (int i = 0; i < threads_num_; ++i) {
workers_.emplace_back([this] { Worker(); });
}
}
~ThreadPoolDouble() {
task_queue_->Cancel();
for (auto &w : workers_) {
if (w.joinable()) w.join();
}
}
void Post(std::function<void()> task) override {
task_queue_->Push(task);
}
private:
void Worker() {
while (true) {
std::function<void()> task;
if (!task_queue_->Pop(task)) break;
task();
}
}
std::unique_ptr<BlockingQueuePro<std::function<void()>>> task_queue_;
};贡献者
最近更新
Involution Hell© 2026 byCommunityunderCC BY-NC-SA 4.0![]()
![]()
![]()
![]()